빅데이터의 꽃은 단연 머신러닝이라 생각한다.
우리의 궁극적 목표는 머신러닝의 발자취를 따라가는 것.
머신러닝의 가장 기초는 데이터를 처리하는 데에 있다.
▼ 데이터 처리 단계
데이터 처리 단계 : [수집] -> [저장] -> [처리] -> [분석] -> [시각화]
웹에서는 기본적으로 [수집] -> [저장] -> [처리] -> [분석] -> [시각화] 단계로 이루어진다.
기본적으로 웹 스크래핑, IOT 센서, JSON/CSV/TEXT 등 공용,공개, 공공데이터, SQL, SNS 등의 상호 수집 데이터 등을 이용해서 데이터를 수집하는데, 이러한 데이터를 저장하는 것이 중요한 이유는 데이터 아키텍처의 시스템을 따르기 때문이다.
기업은 최소의 비용으로 최대 효율을 따지기 때문에 데이터 저장을 할 때에 클라우드 등의 시스템을 사용한다. 하지만 보안성이 중요한 곳의 경우 클라우드를 사용하지는 않는다.(셋방을 쓰는 개념, root 최고 관리자는 데이터에 언제든지 접근이 가능하기 때문이다.) 데이터는 csv, text, xml, sql, TF, IDF 등의 형태로 저장된다. 데이터들을 처리하려면 일단 가공이 필요한데, 가공된 데이터는 분석과 시각화가 함께 진행된다. 데이터의 정보를 효과적으로 전달하기 위해서는 시각화가 좋은 수단이기 때문이다.
요즘은 분석으로 끝나지 않는다. 과거의 데이터를 보고 미래를 예측한다. 회귀분석과 신뢰구간 등 확률을 통해 예측을 한다. 또한 데이터를 해서 수치화를 하고 이를 통해 알고리즘 훈련, 머신러닝 등 분석과 동시에 기계학습을 시키기도 한다. 즉, 기계학습의 목적은 미래를 예측하는 것이다.(그래 이거!!! 나나나 이거할래)
가장 기초적인 데이터 [수집] 단계부터 시작해보자.
[ BeautifulSoup ]
웹 크롤링을 위한 파이썬 라이브러리
웹에서 정보 긁어오기
1. 개념
1.1. 웹 스크레핑(web scraping)
웹 사이트 상에서 원하는 부분에 위치한 정보를 컴퓨터로 웹 사이트들에서 원하는 정보를 추출하여 수집하는 기술 (특정 페이지의 HTML 문서에 소스들 중에서 원하는 정보만 추출하는 기술)
1.2. 웹 크롤링(Web crawing)
자동화 봇(bot)인 웹 크롤러(web crawler)가 정해진 규칙에 따라 복수 개의 웹 페이지를 브라우징 하는 작업. 즉, 웹에서 표현되는 정보를 프로그램을 작성해서 정규화된 정보로 긁어오는 행위를 말한다.
2. 웹 스크래핑을 위한 라이브러리
2.1. BeautifulSoup : 파이썬 스크래핑 라이브러리
2.2. scrapy : 크롤링과 스크래핑을 간편하게 도와주는 프레임워크
3. 옵션
html.parser (기본 파서, 적당하게 빠른 수준)
lxml -> lxml(html), xml (xml을 사용한다면 제공받는 파서, 외부 C라이브러리에 의존 단점, 속도가 빠름)
html5lib -> python2전용 , 아주 느리다. 웹브라우저의 방식으로 페이지를 해석한다.
BeautifulSoup
1. 개념
BeautifulSoup 기본적으로 HTML을 온전하게 불러올 수 있도록 도와주는 모듈이다.
원래 HTML은 태그로 이루어져 있고, 수많은 공백과 변화하는 소스들 때문에 오류가 있을 수도 있어, 정규표현식등으로 불러오기 힘들다. 하지만 beautifulsoup을 이용하면 알아서 이러한 오류를 잡아서 고친 후 우리에게 데이터를 전달해준다.
2. 단계
BeautifulSoup 3가지 단계를 거친다.
1. request : 웹페이지의 URL을 이용해서 HTML 문서를 요청
2. response : 요청한 HTML 문서를 회신
3. parsing : 태그 기반으로 파싱(일련의 문자열을 의미있는 단위로 분해)
이러한 3가지 단계를 거쳐 크롤링을 수행한다.
3. 메소드/속성 미리보기
- title 태그 안의 텍스트를 가지고 오고 싶을 때 : soup.title.getText() 또는 soup.title.text
- 태그 자체를 가져오고 싶을 때 : soup.title
- 태그가 유니크하지 않은 경우, 특정 정보를 불러오고 싶을 때 ex) div 태그가 여러개
: soup.div.next_sibling 속성을 사용 / soup.find_all('div') / id나 class의 이름을 통해 크롤링
- 태그 안의 속성의 정보를 불러오고 싶을 때 : soup.find('div')['id'] -> 속성을 딕셔너리처럼 넣어줌
[ 파이썬 스레딩 모듈을 사용해서 데이터 스크랩핑하기 ]
find / find_all / select / select_one
1. 파이썬 내부에서 html 태그를 이용해 크롤링하기
1) html 코드 작성
우선 태그의 쓰임을 알아보기 위해 간단하게 html 코드를 작성해보자. html 코드는 """ 사이에 입력해줄 수 있다.
기본적으로 pip를 이용해서 BeautifulSoup을 설치했다 가정.
from bs4 import BeautifulSoup
#분석하고 싶은 html
html = """
<html>
<body>
<h1>나의 첫번째 웹스크래핑!</h1>
<p>첫번째 라인</p>
<p>두번째 라인</p>
<p><b>여기를 출력하시오</b></p>
</body>
<html>
"""
2) html 파싱
html을 파이썬에서 읽을 수 있게 파싱한다. 즉, 파이썬 객체로 변환하는 것.
html이라는 변수에 저장한 html 소스코드를 .parser를 붙여 변환해준다.
parser는 파이썬의 내장 메소드이다.
soup=BeautifulSoup(html,'html.parser')
3) 태그로 접근하기
html에 접근하는 가장 기본적인 방법은 태그(DOM의 연산자)를 사용하는 것이다.
.연산자를 사용해서 Document Object 주소로 접근하는 방법은 대표적으로 두가지.
- tag.name(. 왼쪽에 있는 애가 소유주다.)
- tag.subtag.subtag
h1 = soup.html.body.h1
p1 = soup.html.body.p위에서 파싱한 soup의 html 중, body 태그의 <h1>, <p> 요소에 접근한다.

- 부모태그
부모태그를 찾아갈 수도 있다. 이 속성을 이용하면 해당 요소의 부모에 접근할 수 있다.
parent는 바로 상위 부모 요소
parents는 상위의 모든 조상 요소
hp1=h1.parent
print(hp1)hp2 = h1.parents
print(hp2)
print(type(hp2))

hp2의 경우, generator 는 향후에 반복문으로 풀어주어야 원하는 값으로 출력이 가능하다.
▼왜 태그가 안나와?
generator 라는 오브젝트가 리턴 됐습니다. 제너레이터는 자신이 리턴할 모든 값을 메모리에 저장하지 않기 때문에 조금 전 일반 함수의 결과와 같이 한번에 리스트로 보이지 않는 것입니다. 제너레이터는 한 번 호출될때마다 하나의 값만을 전달(yield)합니다. 즉, 위의 코드까지는 아직 아무런 계산을 하지 않고 누군가가 다음 값에 대해서 물어보기를 기다리고 있는 상태입니다.(참조 링크)
<p>태그는 여러개이다. p태그를 가져오면 어떻게 될까?
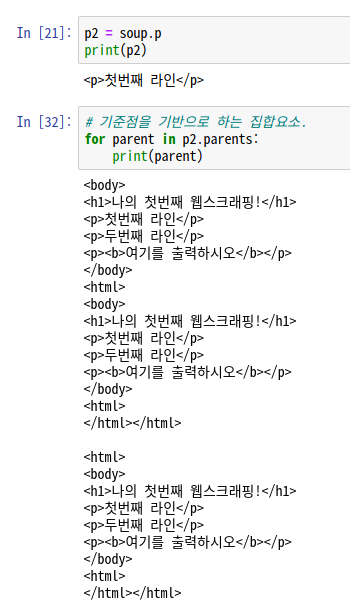
p2 = soup.p
print(p2)가장 상위의 <p>태그만 가져온다.
위에서 hp2는 generator 형식으로 출력되어 반복문으로 풀어주었어야 했었다.
p2를 반복문으로 풀어보자.
for parent in p2.parents:
print(parent)반복문으로 풀어주게 되면, 현재 존재하는 <p>태그의 갯수만큼 반복된다.
차례대로 살펴보면,
1. 처음 '첫번째 라인'이 적혀있는 태그를 기준으로 부모인 <body>까지 출력
2. <body>태그 위의 <html>까지 출력
3. <html> 상위태그가 없으므로 한번 더 출력
가 된다. 이런식으로 반복문을 통해 풀어낼 수 있다.
- 형제 태그
동일한 (들여쓰기)위치에 있는 형제들을 불러올 수 있다.
- next_siblings : 동일한 위치에 있는 바로 다음 형제들 요소
- previous_siblings : 동일한 위치에 있는 바로 이전 형제들 요소
- next_element : 바로 다음 형제 내용
- previous_element : 직전 형제 내용
print('p2:',p2)
print('p2.next_element:',p2.next_element)
print('p2.next_sibling:',p2.next_sibling)
print('p2.previous_element:',p2.previous_element)
print('p2.previous_sibling:',p2.previous_sibling)↓결과창이 원래 이렇게 나와야한다.
p2: <p>첫번째 라인</p>
p2.next_element: 첫번째 라인
p2.next_sibling: <p>두번째 라인</p>
p2.previous_element: 나의 첫번째 웹스크래핑!
p2.previous_sibling: <h1>나의 첫번째 웹스크래핑!</h1>
↓나는 아래 사진처럼 나왔는데, 원래 공백도 dom 요소의 값으로 포함되기 때문에, 공백이 없어야 위처럼 출력된다.

next_sibling은 다음 형제 요소. 즉, p2의 첫번째 라인이 아닌 두번째 라인이 출력되고, previous_sibling의 경우 그 이전의 <h1>태그가 출력된다.
위처럼 공백을 지울 수 없을 때에는 두번 쓰면 된다.
p2=p1.next_sibling.next_sibling
p3=p2.next_sibling.next_sibling
print(p3)
print(p2)<p>두번째 라인</p>
<p><b>여기를 출력하시오.</b></p>
공백 없이 잘 나오게 된다.
- 태그 안의 텍스트만 출력하기
print(p3.b.string)여기를 출력하시오.
string을 쓰면 태그 안의 텍스트를 출력할 수 있다.
- children() : 바로 하위의 자식요소. 내용을 인식하지 않기 때문에 이것도 for문으로 풀어준다.
b = p3.b.children
print(b)
for x in b:
print(x)<list_iterator object at 0x7f8d392f02e8>
여기를 출력하시오.
2. id와 class를 이용한 웹스크래핑
1) 새로운 html 입력 및 파싱
html2 = """
<html>
<body>
<h1 id = 'title'>Hello Python</h1>
<p id = 'body'>웹스크래핑 분석</p>
<p class = 'scp'>웹 스크래핑1</p>
<p class = 'scp'>웹 스크래핑2</p>
<p class = 'scp'>웹 스크래핑3</p>
"""
#파싱
soup = BeautifulSoup(html2,"html.parser")
soup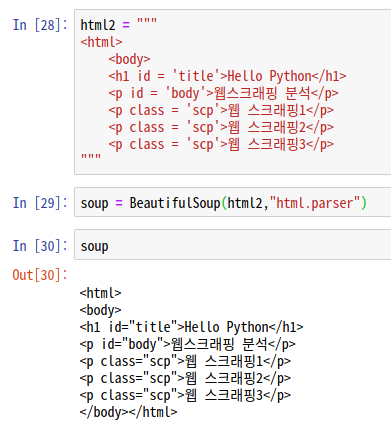
2) 리스트 반환
soup의 내용을 모두 가져와서 리스트로 반환한다.
scnt = soup.contents
print(type(scnt))
print(scnt)
- 배열 형태가 아닌 텍스트로 가져와보자.
for e in soup:
print(e)
3) 공백제거
stripped_strings 은 공백을 제거해준다.
for e in soup.stripped_strings: #공백도 함께 제거해주는 기능
print(type(e))
print("{} => {}".format(e,len(e)))
4) find 함수
Query의 선택자 방식과 비슷하다. id, class, element 등으로 찾을 수 있다.
title = soup.find(id='title')
print(title)
- find() : 조건에 해당하는 첫 번째 정보만 보여줌
- find_all() : 조건에 해당되는 정보를 보여줌
클래스 이름을 알 경우, class_ 형태로 사용한다.
태그 내부 텍스트만 출력할 경우 string을 붙여준다.
- string : get_text() 보다 정확하게 문자열을 추출할 경우 사용. string의 경우 태그를 먼저 인식 후 텍스트를 가져온다.
- get_text() : 현재 태그를 포함하여 모든 하위 태그를 제거하고 유니코드 텍스트만 들어있는 문자열을 반환

웹 스크래핑에서는 원하는 정보를 구체적으로 가져와야하는 경우가 훨씬 많다.
따라서 태그의 속성을 좀 더 자세한 정보를 기입할 수도 있다.
find("태그"{"속성":"속성 이름"}) : 이경우, 불필요한 태그까지 가져올 수 있다.
3. URL 읽기
1) 구글 아이콘 url로 받아오기
urllib 패키지를 이용해서 인터넷 리소스를 가져온다.
urllib.error모듈은 urllib.request에 의해 발생하는 예외에 대한 예외 클래스를 정의힌다.
베이스 예외 클래스는 URLError. 추가로 http 에러도 예외로 추가해준다.
from urllib.request import urlopen
from urllib.error import HTTPError,URLError
try:
url="https://www.google.com/images/branding/googlelogo/2x/googlelogo_color_92x30dp.png"
html=urlopen(url)
except HTTPError: # 에러일 경우
print('Http Exception1')
except URLError:
print('URLError')
else: #정상적일 경우
savename="ikosmo.png"
image=html.read()
print(image)
2) 이미지 저장하기
이미지를 저장해보자.
파이썬에는 기본적으로 제공되는 다양한 모듈이 있다. 자주 사용되는 모듈 가운데 os라는 모듈이 있는데, os 모듈은 Operating System의 약자로서 운영체제에서 제공되는 여러 기능을 파이썬에서 수행할 수 있게 해준다.
여기서는 디렉토리를 여는데에 사용되었다.
mode='wb' -> 바이너리(b) 형태로 쓰기(w)
import os
try: #ikosmo.png 이름으로 저장
with open(savename,mode='wb') as f:
f.write(image)
print('이미지가 저장되었습니다.')
except IOError: #에러 예외처리
print('이미지 저장에 실패했습니다.')
else: #디렉토리 리스트 열기
print(os.listdir())
- urllib.request.urlretrieve를 통한 다운로드
urlretrieve 함수를 통해 바로 파일에 자료를 입력할 수 있다. 아래의 경우 파일에 직접 저장하는 것.
import urllib.request as req
url='https://www.google.com/images/branding/googlelogo/2x/googlelogo_color_92x30dp.png'
req.urlretrieve(url,'ikosmo2.png')
print('저장되었습니다.')
os.listdir()
4. XML 파싱하는 방법
xml(Extensible Markup Language) 파일은 사용자 정의 태그를 사용하여 문서의 구조 및 기타 기능을 설명하는 일반 텍스트 파일이다. 우리가 흔히 아는 <body>,<h1>,<p> 이런 태그가 아니라 <student>, <apple> 이런 식의 사용자가 표시할 수 있는 태그다. HTML과 유사한 문법을 사용하고, 컴퓨터(PC-스마트폰)간에 정보를 주고받기 매우 유용한 저장방식이다.
▼XML 예시?(RSS)
RSS 란? [Really Simple Syndication 또는 Rich Site Summary]
어떤 사이트가 있을 때, 그 사이트를 매일 방문해서 재미있는 새로운 기사가 있는지 확인하는 것은 번거롭다. 이럴 때 블로그의 배너같은 위치에 RSS를 설치하면 그 사이트를 직접 방문하지 않고서도 새로운 기사들이 내 배너에 '배달'된다. 이처럼 RSS와 같은 사이트 피드는 새 기사들의 제목만 또는 새 기사들 전체를 뽑아서 하나의 파일로 만들어 놓은 것이다.
RSS는 대표적인 XML 형식이다.
<rss>
<songinfo>
<song singer="singer1" album="album1">
<title>Track1</title>
<length>3:15</length>
</song>
<song singer="singer2" album="album2">
<title>Track2</title>
<length>2:22</length>
</song>
<song singer="singer3" album="album3">
<title>Track3</title>
<length>5:33</length>
</song>
<song singer="singer4" album="album4">
<title>Track4</title>
<length>4:33</length>
</song>
</songinfo>
</rss>보통 이런식의 태그를 사용하는데, 사용자가 알 수 있는 태그로 묶어놓았다.
1) xml 데이터 수집을 위해 import 하기
#xml 데이터를 가져오는 방법
import urllib.request
import urllib.parse
#기상청 육상 중기예보
API = "http://www.weather.go.kr/weather/forecast/mid-term-rss3.jsp"2) API에 옵션을 부여해 새로운 url 생성
values={"stnId":"109"} #서울/경기
#URL에 한글, 특수문자가 포함될 경우
params=urllib.parse.urlencode(values)
#요청 url 생성
url=API + "?" + params
print("url=",url)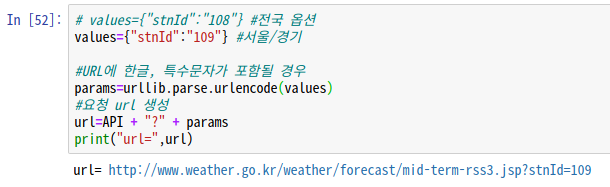
3) 다운로드 하기
#다운로드
data=urllib.request.urlopen(url).read()
print(data)
4) 한글 형식 갖추고 xml 파일로 가져오기
text=data.decode("utf-8")
print(text)
#다운로드
req.urlretrieve(url,'kma.xml')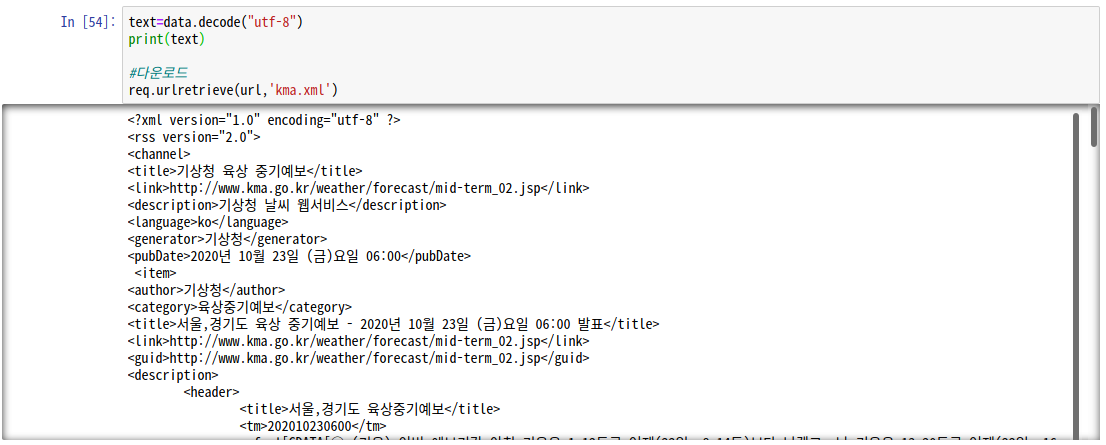
5) 다운받은 디렉토리 확인
6) 2번에서 생성한 URL로 내용 가져오기
# 1. URL로 응답값을 받아온다.
res = req.urlopen(url)
#2. 파싱
soup = BeautifulSoup(res,'html.parser')
#3. 원하는 데이터를 추출 -> findall은 다
title = soup.find('title').string
print('제목 :',title)
wf = soup.find('wf').string
print('날씨 :',wf)
find 함수를 사용해서 'title' 태그와 'wf' 태그를 찾아 그 내용을 가지고 왔다.
타입을 확인해보자.
print(type(wf))
<wf>태그 안에 CDATA가 있음을 확인할 수 있다.

- CDATA
XML 문서를 보면 가끔 <![CDATA[ ... ]]>와 같은 태그로 감싸져있다.
CDATA는 'Character Data'. 즉, '문자 데이터'를 말한다. 정확히는 '(Unparsed) Character Data'. 즉, '파싱하지 않는 문자 데이터'라는 뜻이다. 반대로, 파싱하는 문자 데이터는 'PCDATA'라고 부른다.
▼CDATA 사용 이유
예시(출처)
<?xml version="1.0" encoding="UTF-8"?>
<dictionary>
<term>
<entry>볼드</entry>
<description>글씨를 굵은 글씨로 강조한다. <b>...</b> 태그를 사용한다.
<b> 대신 <strong>을 사용해도 된다.</description>
</term>
</dictionary>이러한 XML 파일이 있고 이를 파싱을 했다 가정하자. 그럼 결과는 다음과 같다.
볼드
글씨를 굵은 글씨로 강조한다. ... 태그를 사용한다. 대신 을 사용해도 된다.
description 안에 내용은 html 식으로 본다면 <body>태그와 역할이 비슷하다. XML은 사용자 정의 태그이기 때문에 이와 같은 명확한 파싱 대상 인식이 쉽지 않다.
이 경우, 파싱을 할 수 없게 만드는 CDATA를 사용한다.
<?xml version="1.0" encoding="UTF-8"?>
<dictionary>
<term>
<entry>볼드</entry>
<description><![CDATA[글씨를 굵은 글씨로 강조한다. <b>...</b> 태그를 사용한다.
<b> 대신 <strong>을 사용해도 된다.]]></description>
</term>
</dictionary>볼드
글씨를 굵은 글씨로 강조한다. <b>...</b> 태그를 사용한다. <b> 대신 <strong>을 사용해도 된다.
CDATA 안의 태그는 태그로 인식하지 않는다. 파서가 잘못 파싱할 수 있는 텍스트를 다룰 때, 파서의 잘못된 파싱을 방지할 수 있게 하는 것이다.
ex) HTML 태그를 텍스트 데이터로 쓸 경우
7) 필요 없는 태그 대체하기
CDATA로 인해 내용을 보호하느라 <br>태그까지 포함되었다. 지워버리자.
print(wf.replace('<br />',''))
깔끔하게 출력되었다. :)
5. 태그 속 속성값 크롤링하기
1) 링크가 걸린 html 파일 생성, 파싱
html = """
<html>
<body>
<ul>
<li><a href='http://naver.com' class='test'>naver</a></li>
<li><a href='http://nate.com' class='test'>nate</a></li>
<li><a href='http://google.com' class='test'>google</a></li>
<li><a href='http://yahoo.com' class='test'>yahoo</a></li>
<li><a href='http://daum.net' class='test'>다음</a></li>
</ul>
</body>
</html>
"""
soup = BeautifulSoup(html,'html.parser')
2) test라는 클래스 이름을 가진 태그를 3개 가져오기
links = soup.find_all(class_='test',limit=3)
print(type(links))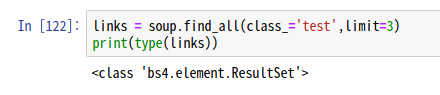
find_all(class_='test')의 type은 <class 'bs4.element.ResultSet'>이다.
ResultSet은 복수의 item을 가진 list이다.
따라서 list형태로 되어있기 때문에 for문으로 List를 순회하면서 get_text() 함수를 사용해야한다.(find는 가능)
3) for문으로 분리해주자.
attrs는 속성을 의미한다. href 속성도 따로 가져오자.
for a in links:
print(type(a))
href = a.attrs["href"]
print(href)
print(a)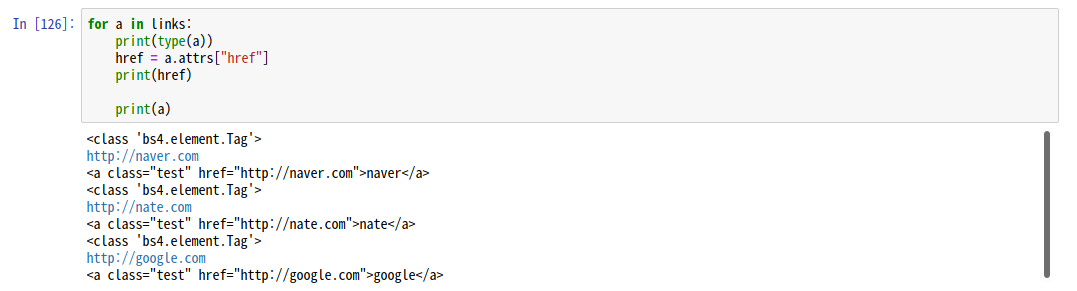
태그 안의 링크를 텍스트로 가져왔다.
6. [과제] 기상청 사이트에서 제주도의 title 태그의 텍스트와 wf 태그 내부의 텍스트만 출력하시오. 단, br 태그는 제거하시오.(5개의 데이터만 추출할 것.)
import urllib.request as req
import urllib.parse as par
API = "http://www.weather.go.kr/weather/forecast/mid-term-rss3.jsp"
values={"stnId":"184"}
params=par.urlencode(values)
url=API + "?" + params
print("url=",url)
res=req.urlopen(url)
soup=BeautifulSoup(res, "html.parser")
title=soup.find("title").string #title 태그 내부의 텍스트
wf=soup.find_all("wf", limit=5) #wf 태그 내부의 텍스트
print(title)
print('===========================')
for w in wf:
print(w.string.replace('<br />',''))
'[ 빅데이터 ]' 카테고리의 다른 글
| [빅데이터] 리눅스 / Selenium 설치 및 사용법 (0) | 2020.10.23 |
|---|---|
| [빅데이터] 웹 크롤링 : BeautifulSoup(2) : select, css selector, pandas (0) | 2020.10.23 |
| [빅데이터] 프로젝트 - 상품등록 페이지 만들기(2) (0) | 2020.10.20 |
| [빅데이터] 프로젝트 - 상품등록 페이지 만들기(1) (0) | 2020.10.19 |
| [빅데이터] 홈페이지 만들기(3) : 파이썬으로 파일 업로드 앱 만들기(cnn, 이미지분류) (1) | 2020.10.17 |