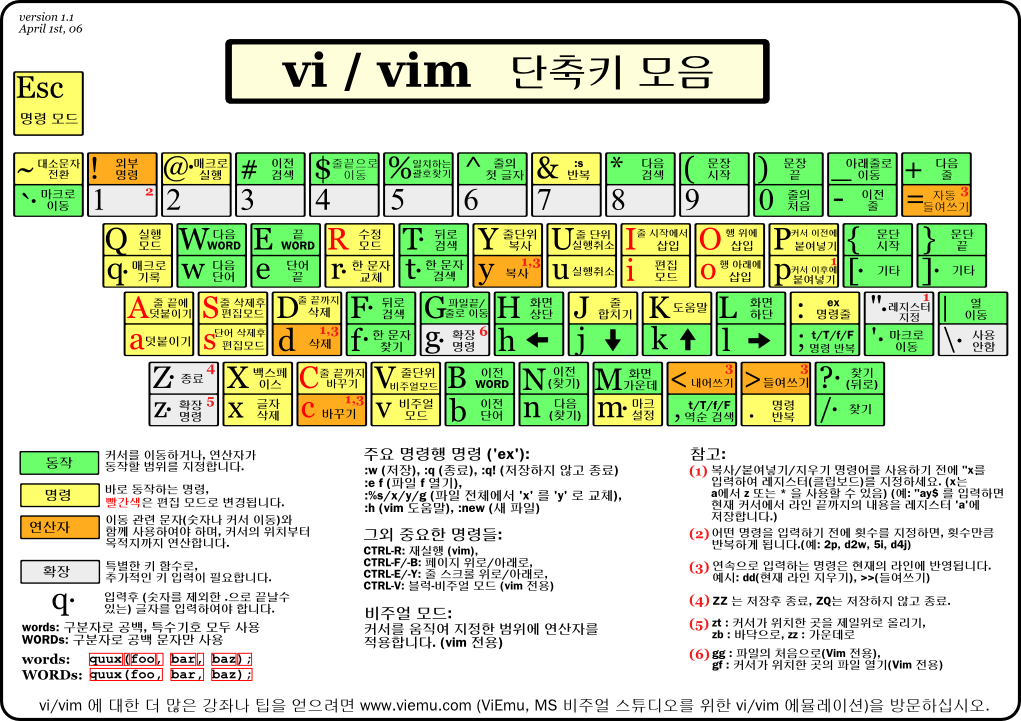
vi 편집기는 유닉스 계열에서 가장 많이 사용되는 편집기이다. 1976년 빌조이가 개발하였다. vi 편집기는 한 화면을 편집하는 비쥬얼 에디터 ( Visual Editor ) 이다.
VI ( Visual Editor ) 편집기의 특징
vi는 Emacs와 함께 Unix 환경에서 가장 많이 쓰이는 문서 편집기이다. 1976년 빌 조이가 초기 BSD 릴리즈에 포함될 편집기로 만들었다. vi라는 이름은 한 줄씩 편집하는 줄단위 편집기가 아니라 한 화면을 편집하는 비주얼 에디터라는 뜻에서 유래했다. 간결하면서도, 강력한 기능으로 열광적인 사용자가 많다.
현재는 오리지널 vi를 사용하는 경우는 거의 없고, 일반적으로 기능을 모방하여 만들어진 클론을 사용하고 있다. 이런 클론 중 많이 쓰이는 것은 기능이 다양한 것을 장점으로 내세우며, 리눅스 배포판에 포함되는 Vim, 그리고 BSD 라이센스로 제공되며 원본 vi의 동작과 호환성으로 정평이 나 있는 nvi, 독자적인 팬층을 확보한 elvis 등이 있다.
vi 편집기가 동작하는 원리를 보면 버퍼에서 작업을 하게 된다. 그러므로 저장을 시키는 명령어를 입력하지 않는 이상 디스크상에 파일의 내용으로 저장되는 것은 아니다.
마태 자하리아가 UC 버클리에서 박사 과정 논문의 일부로 개발한 강력한 오픈소스 분산 쿼리 및 처리 엔진. 다양한 종류의 데이터 관련 문제, 예를 들어 반구조(semi-structured), 구조, 스트리밍 또는 머신 러닝/데이터 과학 관련 문제를 해결하기 위해 쉽고 빠르게 쓸 수 있는 프레임워크이다.
스파크는 데이터를 읽고, 변형하고, 합계를 낼 수 있으며, 복잡한 통계 모델들을 쉽게 학습하고 배포할 수 있다.
파이썬 pandas 라이브러리와 R의 data.frames 또는 data.tables를 이용하는 데이터 분석가, 데이터 과학자 또는 연구우너들에게 적합한 여러 라이브러리를 제공한다.
<에러> Vagrant failed to initialize at a very early stage: There was an error loading a Vagrantfile....
-> 웹에서 붙여넣은 거기 때문에 공백이 존재할 수 있음. 필요없는 공백 다 지우고 다시 해보면 됨.
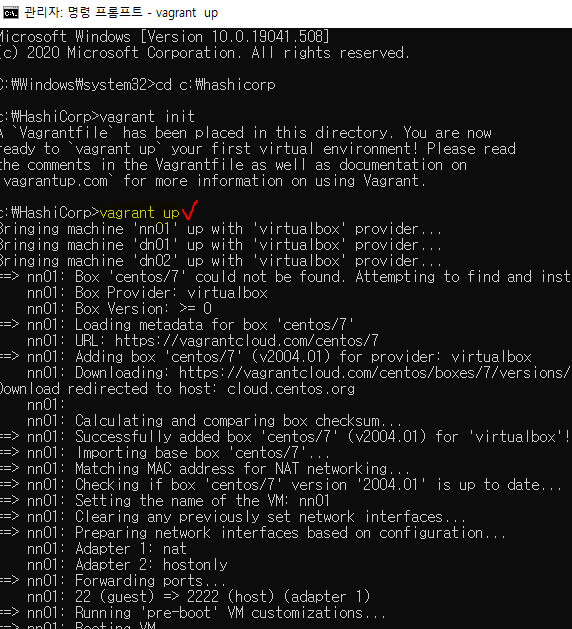
4. 가상머신 기동
- 다시 cmd 돌아와서 vagrant up 입력하면 설치됨
좌:명령어 우:완료된 화면
<에러> 갑자기 다운로드가 잘 되다가 멈춰서 안되면, 도스창에 아래 사진처럼 마우스 커서를 뒀을 확률이 높다.
방향키를 클릭해서 다운로드를 이어서 해주면 된다.
이경우 재부팅이 아닌 방향키를 눌러준다.
- C 드라이브 > user > VirtualBox VMs에 가상 폴더 3개가 만들어져 있어야 함. 없으면 설치가 제대로 되지 않은 것.
Vagrant(베이그랜트)란
경량화된 Virtual machine 관리 서비스이다.
OS를 직접 하나씩 설치하지 않고 단순히 이미지 형태로 OS를 설치할 수 있다는 것을 말한다.
그래서 Vagrant를 이용하기 위해서는 가상머신이 설치되어 있어야 한다.
참고로 default는 virtual box이다.
+
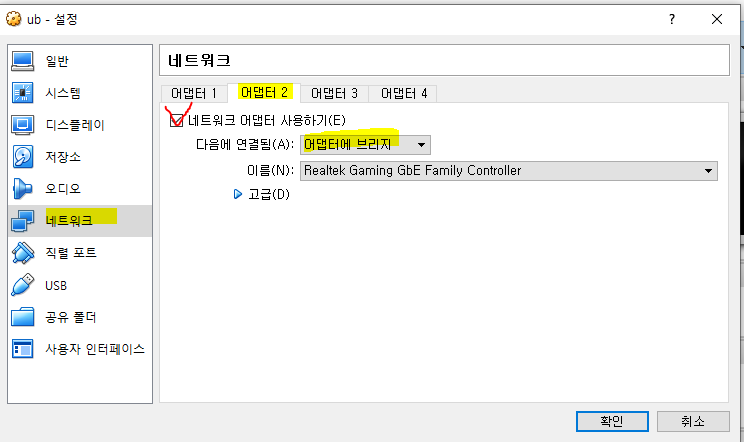
가상장치에서는 네트워크 잡는게 제일 어렵다.
(하루가 다르게 안잡히는 등 에러가 많음.)
베이그랜트는 그러한 작업 없이 알아서 네트워크를 잡아주고
오라클 설치, ip를 잡아주는 등 번거로움을 없애준다.
추가로 공부를 원하면 docker를 공부해볼 것.
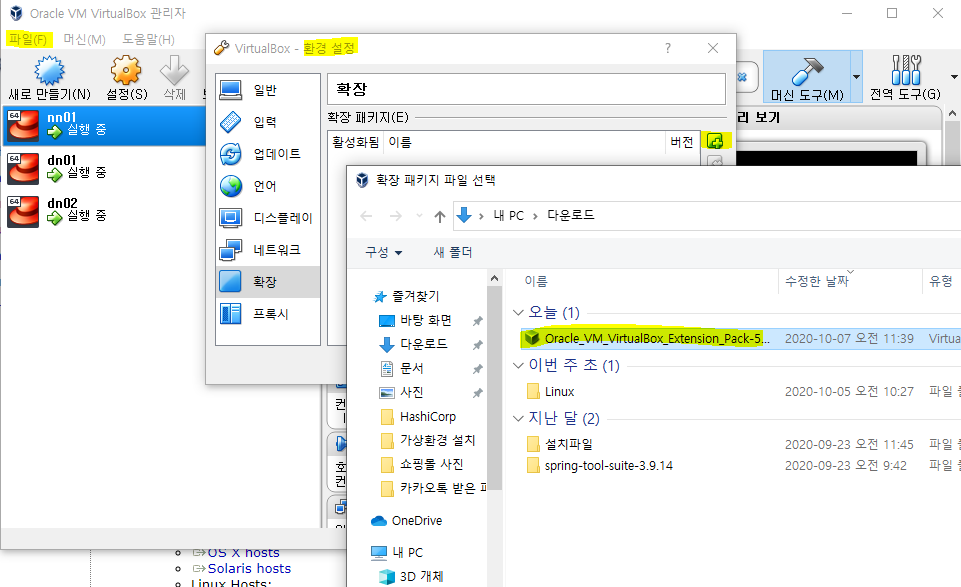
5. Oracle VM VirtualBox 서버 로그인
- Oracle VM VirtualBox을 관리자권한으로 실행하면 nn01/dn01/dn02 가상머신(서버)이 생김
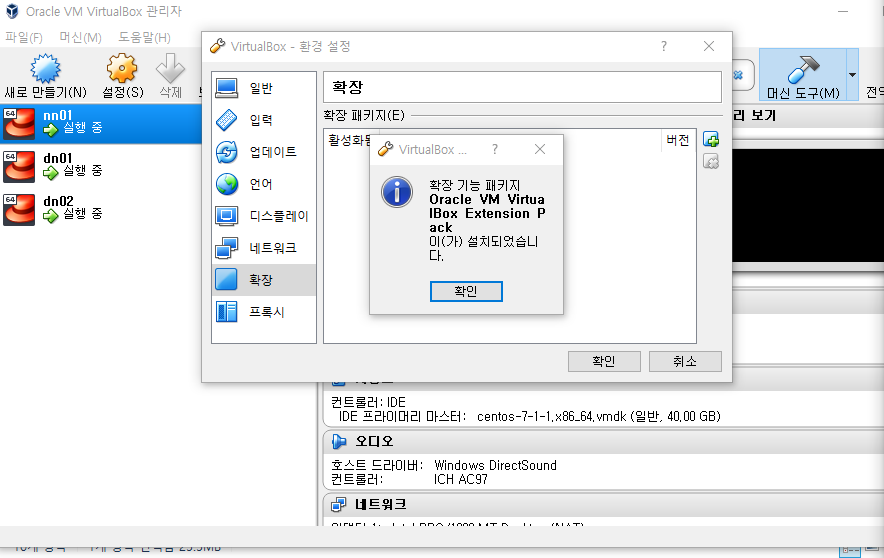
- 확장판 불러오기 : 파일 > 환경설정 > 확장 > + > 확장판 설치
확장판 설치
- nn01 / dn01 / dn02 각각 더블클릭하면 각각의 가상환경에서 리눅스가 켜진다.
login : root/vagrant
vagrant/vagrant
2개의 계정이 만들어져 있는데 우선 root 계정으로 접속 확인
로그인 : root/vagrant 셋다 root로 접속하기
마우스가 잡히면 오른쪽 shift 키로 벗어나자.
<참고> 마우스 벗어나는 키 바꾸는 법 : 환경설정 > 입력 > 가상머신 (탭) > 단축키 수정
나는 ctrl + alt로 설정함.
<참고>파일 >가상환경 내보내기 하고 다른장치에서 불러오면 지금 장치가 그대로 다시 불러올 수 있다.
6. putty / MobaXterm 설치
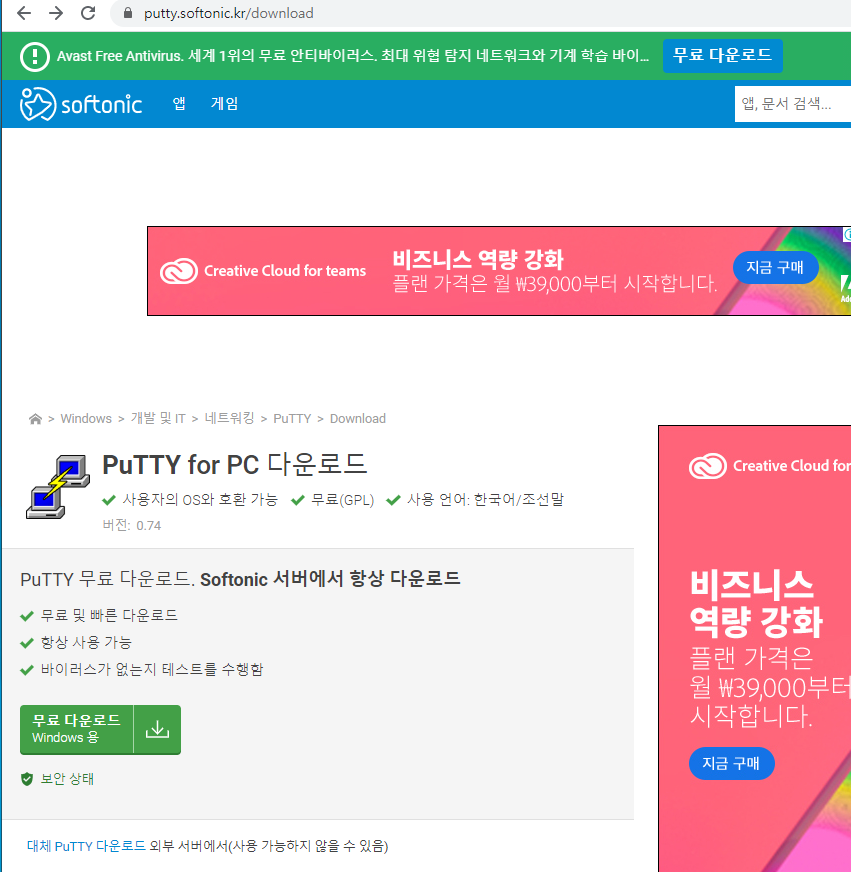
현재까지 서버에 직접 접속한 것이다. 만약 집에서 회사 서버로 접속하려면? -> putty 를 설치한다.- https://putty.ko.softonic.com/ 에서 무료 다운로드 > putty-0.70-installer.msi 더블클릭 후 설치 > 실행
- https://mobaxterm.mobatek.net/ 에서 GET MOBAXTERM NOW! > Home Edition Free 다운로드 > potable edition 다운로드(압축 풀고 MobaXterm_Personal_20.3 실행)
putty 설치
PUTTY
리눅스 시스템 터미널을 활용하기 위해서는
PUTTY 등의 다양한 SSH(보안셸) 관련 프로그램을 이용하여
원격지에서 호스트 접속을 위한 프로토콜 프로그램을 필요로 한다.
기존 원격접속 기능에 암호화 기능을 추가한 것.
양쪽 리눅스를 GUI로 설치하면 대부분 사용 가능하다.
MobaXterm
MobaXterm 은 원격 컴퓨팅 toolbox이다.
단일 윈도우 응용 프로그램으로
다양한 연결방식을 제공한다.
물론 putty 를 사용하는 사람들에게도 필요한 원격 작업들을 제공한다.
Home Edition 으로 무료로 사용할 수 있으나 ,
최대 12 session / 2 SSH tunnels / 4 macros / 360 초 Tftp 의 제한이 걸려 있다.
7. putty IP연결
- 1) Oracle VM Virtual에서각 노드의 아이피 확인
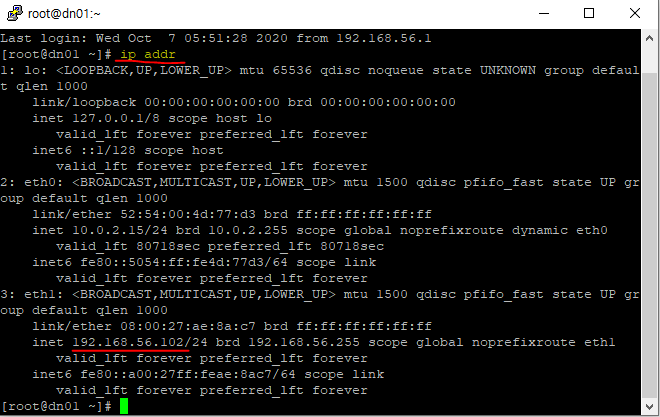
CentOS 7의 최소 설치로 되어 ifconfig 명령어도 없다. 우선 ip addr 로 확인
dn01의 ip 주소 확인
각각 확인해본 ip는 다음과 같다.
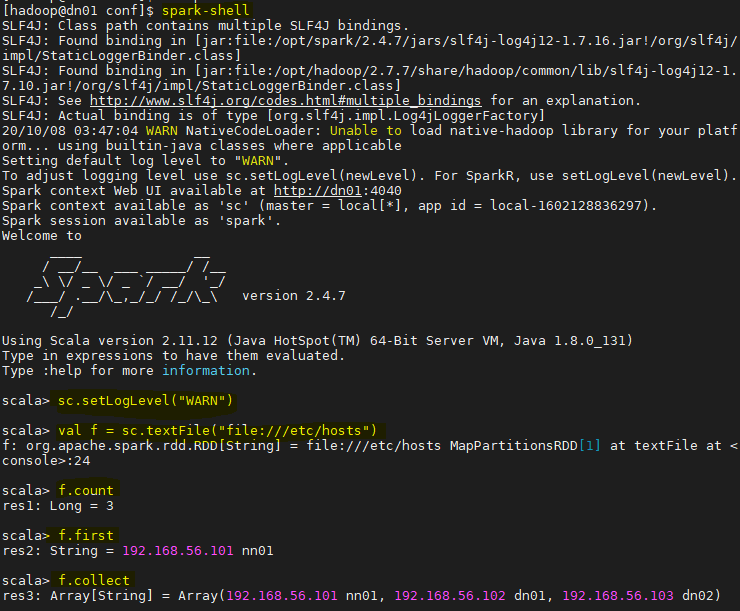
nn01 : 192.168.56.101
dn01 : 192.168.56.102
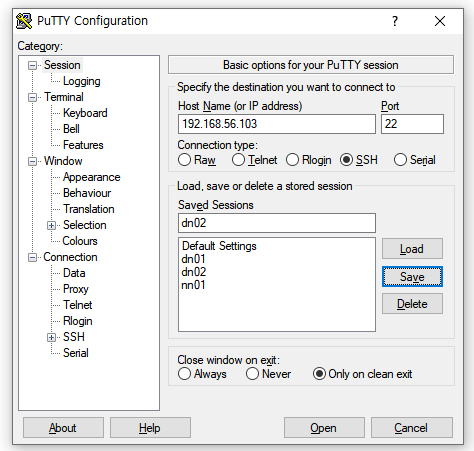
dn02 : 192.168.56.103
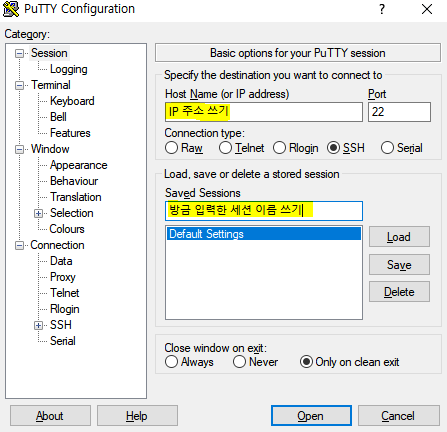
- 2) putty에 연결
Oracle VM Virtual에서 찾은 ip로 putty가 접속할 수 있게 한다.
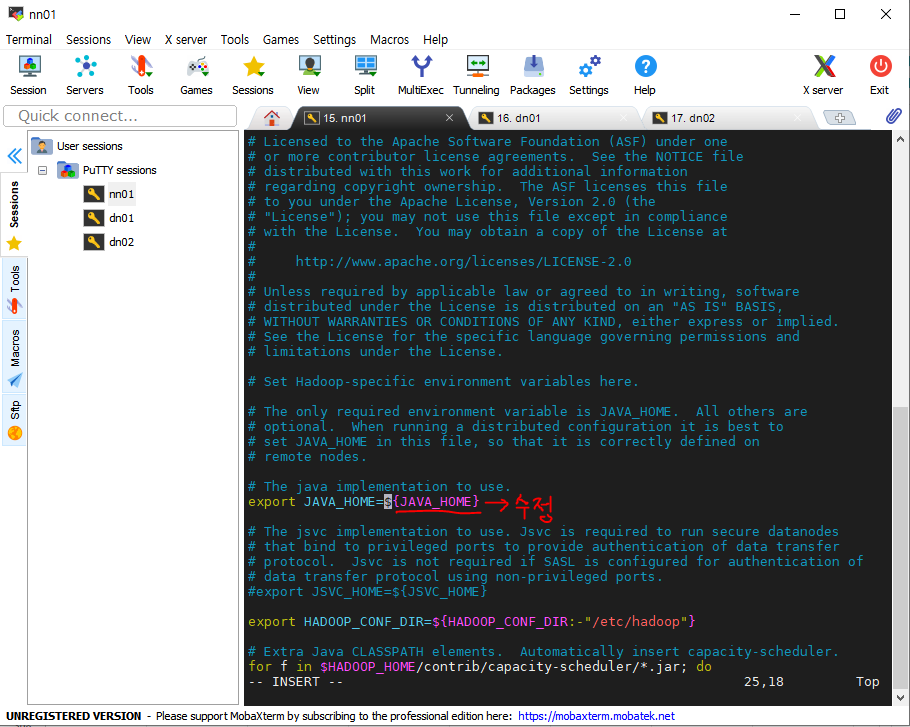
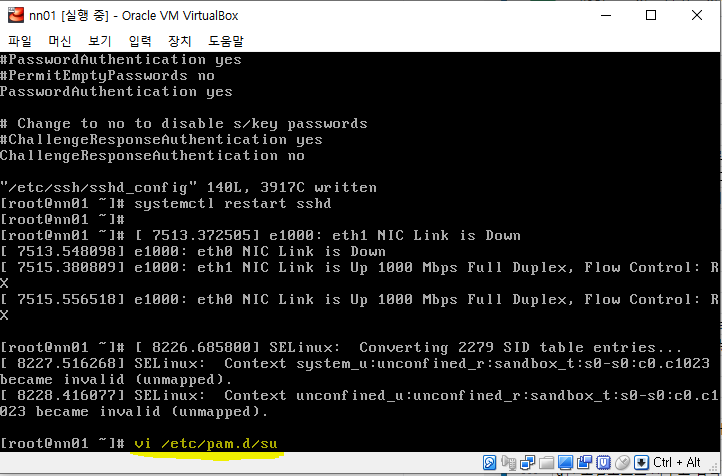
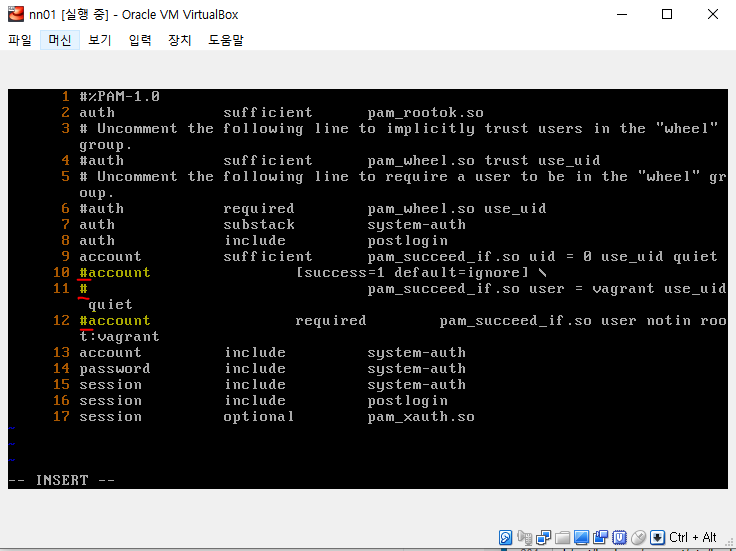
비밀번호 없이 접속이 가능하게끔 vi 에디터를 사용하자.
### 각각의 창에 한줄씩 입력하기 ###
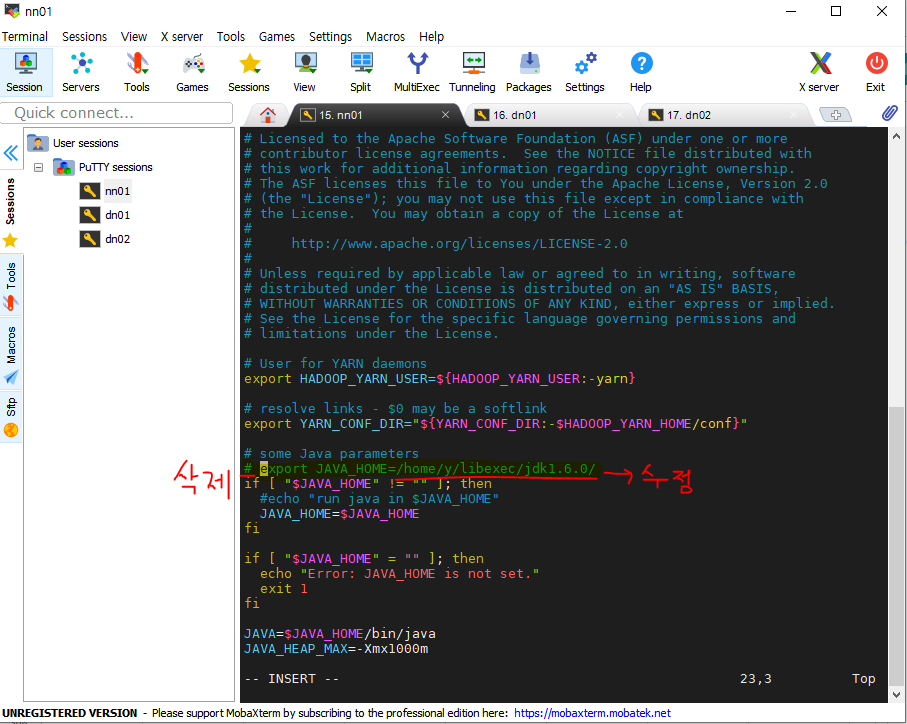
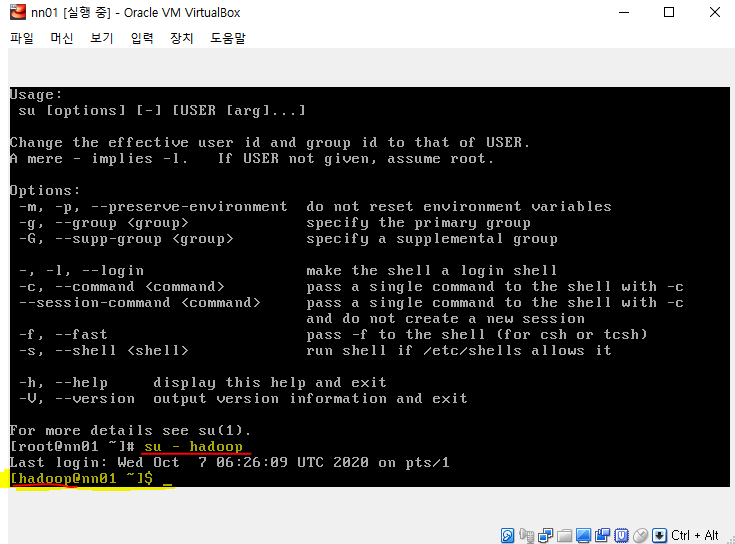
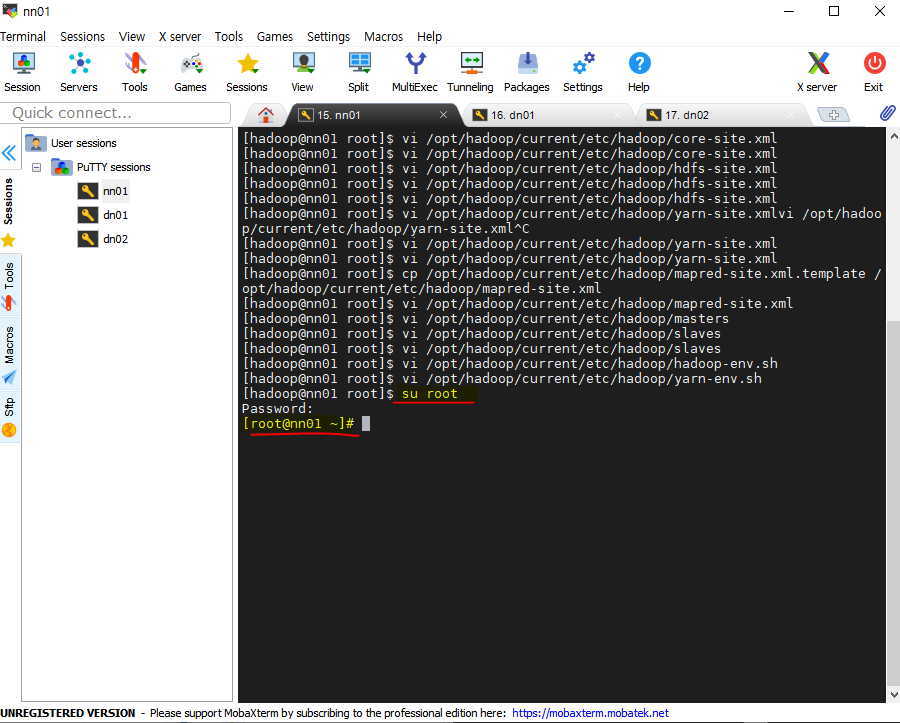
[root@nn01 ~]# vi /etc/ssh/sshd_config /Password-> PasswordAuthentication 찾기 PasswordAuthentication no를 PasswordAuthentication yes로 변경 (다시 vi /etc/ssh/sshd_config 로 들어가서 바뀌었는지 확인하기) [root@nn01 ~]# systemctl restart sshd -> putty에 접속 가능하게 바꿔주기
nn01 외에도 dn01, dn02에도 같은 작업을 한다.
vi 화면 no -> yes로 변경
- 그 후 putty 접속 : IP 주소 쓰고 세션 이름 쓰기 -> save
오른쪽처럼 쓰자.이런 에러 나면 systemctl restart sshd를 안해준거다.
- 결과
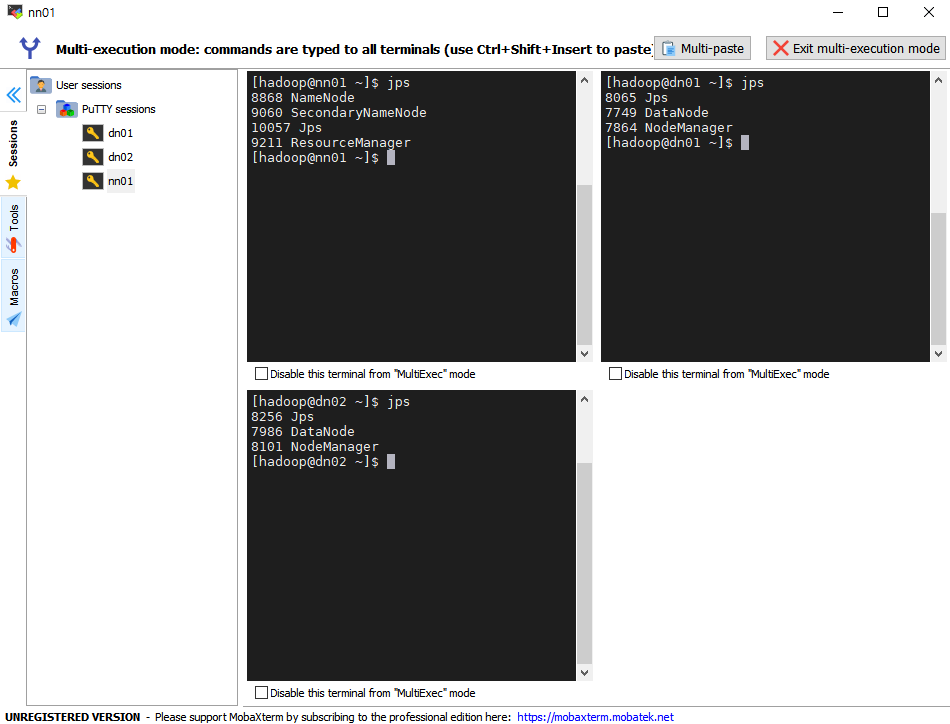
putty로 각각의 컴퓨터에 연결되었다.
<주의> 아래 작업을 하기 전에 putty는 꺼도 되지만 가상머신(Oracle VM Virtual)은 끄면 안된다.
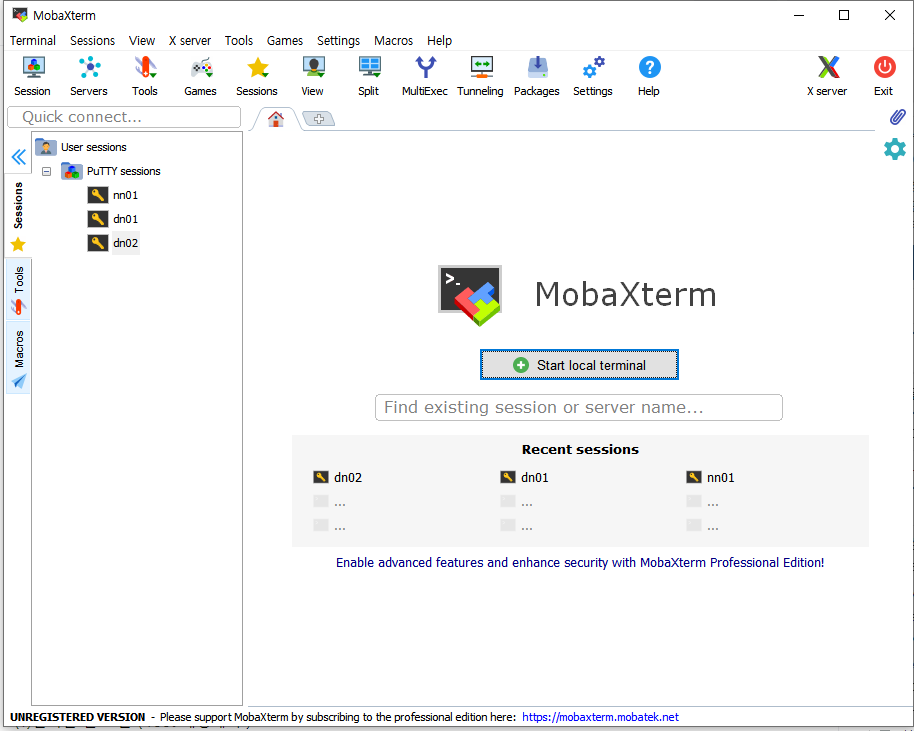
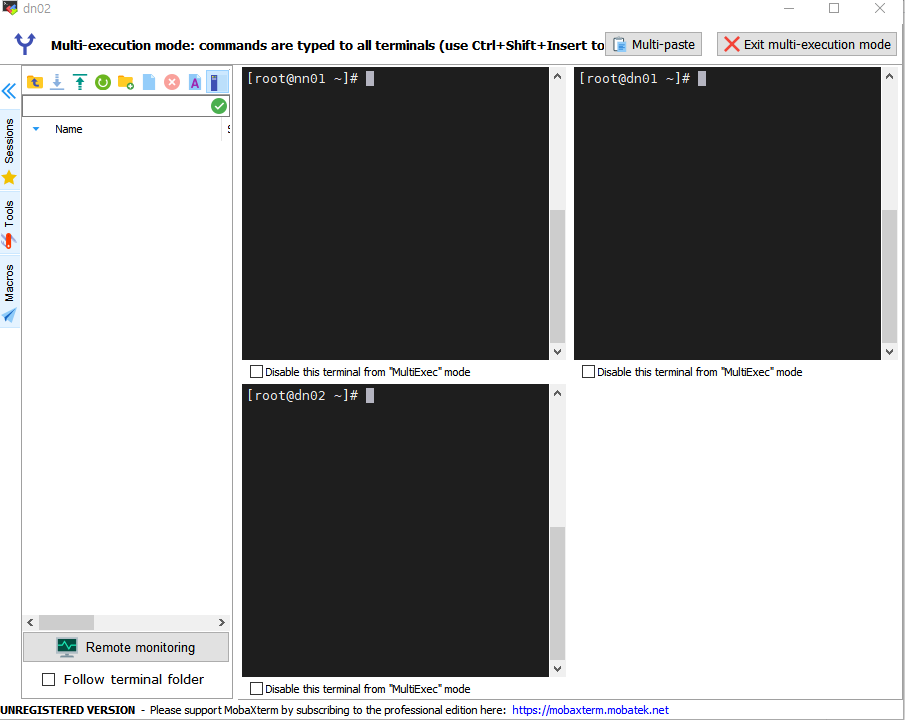
8. MobaXterm 연결
- 각각의 화면으로 띄워서 하면 불편하지 않을까? MobaXterm가 이러한 불편함을 해결해준다.
[root@nn01 ~]# cd /tmp [root@nn01 tmp]# wget https://github.com/protocolbuffers/protobuf/releases/download/v2.5.0/protobuf-2.5.0.tar.gz
- 압축풀기
- 이동시키기(mv)
- 이동되었는지 확인
[root@nn01 tmp]# tar -zxvf protobuf-2.5.0.tar.gz [root@nn01 tmp]# mv protobuf-2.5.0 /opt/ [root@nn01 tmp]# ls /opt
파일이 압축이 풀려서 잘 이동했음.
(3) 설치 ( protobuf 폴더로 이동 )
[root@nn01 tmp]# cd /opt/protobuf-2.5.0/
경로이동
[root@nn01 protobuf-2.5.0]# ./configure [root@nn01 protobuf-2.5.0]# make ( 여기서 에러가 발생하면 ./configure에서 안되는 것임 ) [root@nn01 protobuf-2.5.0]# make install [root@nn01 protobuf-2.5.0]# protoc --version (버전 확인 : 만일 에러 발생시 lfconfig ( 소문자 엘) 후 다시 protoc --version)
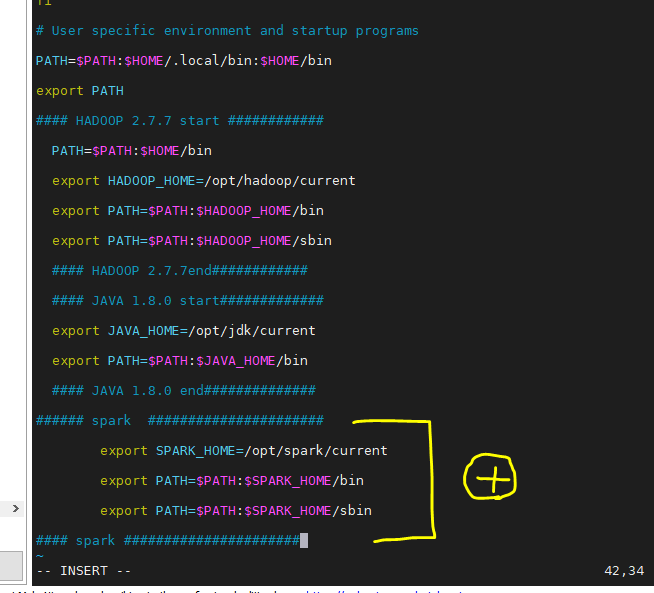
- 다운 받아서 압축 풀고 2.7.7 디렉토리로 전부 이동. current라는 이름의 바로가기 만들기.
[root@nn01 tmp]# cd /tmp
[root@nn01 tmp]# wget http://apache.tt.co.kr/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz ( 다운로드 속도가 너무 느리면 아래에서 다운받기 ) wget https://archive.apache.org/dist/hadoop/common/hadoop-2.7.7/hadoop-2.7.7.tar.gz