1. 오라클 워크시트에 테이블과 시퀀스 생성하기
create table board(
no number CONSTRAINT board_no_pk primary key,
pwd varchar2(10),
writer varchar2(34),
subject varchar2(100),
content varchar2(400),
regdate date default sysdate
);
create sequence board_seq
increment by 1
start with 1;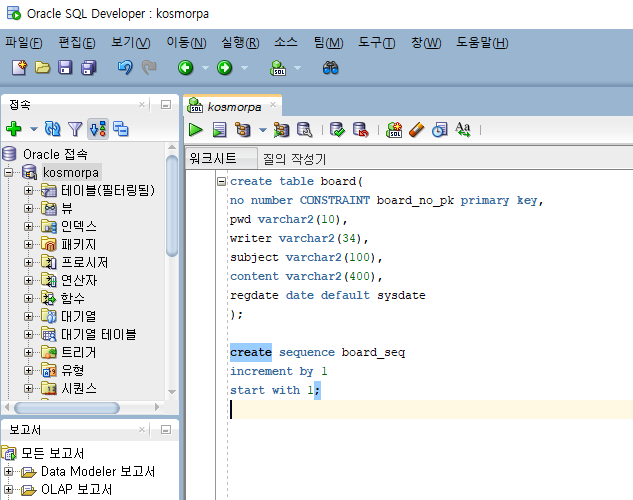
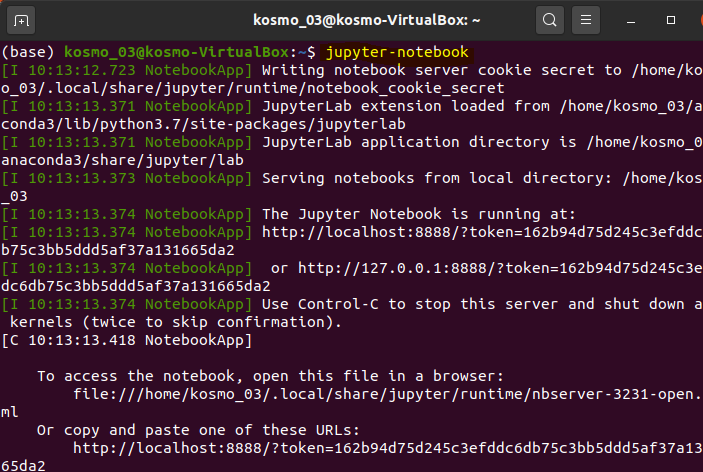
2. 리눅스 터미널에서 jupyter-notebook 실행
(아나콘다가 깔려있어야 한다.)

3. workspace 역할을 할 디렉토리 만들자.
new > folder > 파이썬 파일 하나 만들기

4. 오라클 연동 후 필수 라이브러리 설치
!pip install cx_Oracle 설치하기
!pip install cx_Oracle다운로드 되거나, 이미 설치되어 있으면 이미 했다고 뜸
5. 오라클 연결
#오라클 수입
import cx_Oracle as ora현재 주피터와 오라클 데이터베이스를 연결하는 클래스이다.
앞으로 계속 껐다가 킬껀데, 그때마다 다시 켜주는 장치다.
#오라클 connection 연결
conn = ora.connect('kosmorpa/test00@192.168.0.122:1522/orcl')
print(conn.version)나는 버전이 11.2.0.1.0이다. 저번 포스팅에서 깔았던 그 오라클 버전.
print(conn)
이러면 윈도우에서 오라클 DB가 있어도 리눅스에서 작업할 수 있어서 훨씬 편하다.
6. 커서 변환하기
conn.cursor : 연결된 데이터 베이스에 sql 문장을 실행하고 데이터를 가져오는 역할
#커서 변환하기
cursor = conn.cursor()
print(cursor)
▼ connection 클래스와 cursor 클래스
[ Connection클래스 ]
연결된 데이터베이스를 동작시키는 역할을 한다.
>Connection.cursor()
Cursor객체를 생성한다.
>Connection.commit()
현재 트랜잭션의 변경내역을 DB에 반영(commit)한다.
이 메서드를 명시적으로 호출하지 않으면 작업한 내용이 DB에 반영되지 않으므로, 다른 연결(Connection)에 그 내용이 나타나지 않는다.
>Connection.rollback()
가장 최근의 commit()이후 지금까지 작업한 내용에 대해서 DB에 반영하지 않고, 트랜잭션 이전 상태로 되돌린다.
>Connection.close()
DB연결을 종료한다.
자동으로 commit()메서드를 호출하는것이 아니기에, close()메서드를 호출하기 이전에 commit()/rollback()중 하나를 명시적으로 호출해야 한다.
>Connection.isolation_level
트랜잭션의 격리수준(isolation level)을 확인/설정한다.
입력가능한 값은 None, DEFERRED, IMMEDIATE, EXCLUSIVE이다.
>Connection.execute(sql[, parameters])
>Connection.executemany(sql[, parameters])
>Connection.executescript(sql_script)
임시 Cursor객체를 생성하여 해당 execute계열메서드를 수행한다
(Cursor클래스의 해당 메서드와 동일하므로 Cursor클래스에서 설명하겠다.)
>Connection.create_aggregate(name, num_params, aggregate_class)
사용자정의 집계(aggregate)함수를 생성한다.
>Connection.create_collation(name, callable)
문자열 정렬시 SQL구문에서 사용될 이름(name)과 정렬 함수를 지정한다.
정렬함수는 인자로 문자열 2개를 받으며, 첫 문자열이 두번째 문자열보다 순서가 낮은경우 -1, 같은경우 0, 높은경우 1을 반환해야 한다.
>Connection.iterdump()
연결된 DB의 내용을 SQL질의 형태로 출력할수 있는 이터레이터를 반환
[ Cursor클래스 ]
실질적으로 데이터베이스에 SQL문장을 수행하고, 조회된 결과를 가지고 오는 역할을 한다.
>Cursor.execute(sql[, parameters])
SQL문장을 실행한다. 실행할 문장은 인자를 가질수 있다.
>Cursor.executemany(sql, seq_of_parameters)
동일한 SQL문장을 파라미터만 변경하며 수행한다.
파라미터 변경은 파라미터 시퀸스, 이터레이터를 이용할수 있다.
>Curosr.executescript(sql_script)
세미콜론으로 구분된 연속된 SQL문장을 수행한다.
>Cursor.fetchone()
조회된 결과(Record Set)로부터 데이터 1개를 반환한다. 더 이상 데이터가 없는 경우 None을 반환한다.
>Cursor.fetchmany([size=cursor.arraysize])
조회된 결과로부터 입력받은 size만큼의 데이터를 리스트 형태로 반환한다.
데이터가 없는 경우 빈 리스트를 반환한다.
>Cursor.fetchall()
조회된 결과 모두를 리스트형태로 반환한다.
데이터가 없는 경우, 빈리스트를 반환한다.
출처 : m.blog.naver.com/dudwo567890/130165627205
연결은 끝났고 다양하게 오라클과 연동해보자.
[연동 방식]
- DB 접속이 성공하면, Connection 객체로부터 cursor() 메서드를 호출하여 Cursor 객체를 가져온다. DB 커서는 Fetch 동작을 관리하는데 사용되는데, 만약 DB 자체가 커서를 지원하지 않으면, Python DB API에서 이 커서 동작을 Emulation 하게 된다.
- Cursor 객체의 execute() 메서드를 사용하여 SQL 문장을 DB 서버에 보낸다.
- SQL 쿼리의 경우 Cursor 객체의 fetchall(), fetchone(), fetchmany() 등의 메서드를 사용하여 데이타를 서버로부터 가져온 후, Fetch 된 데이타를 사용한다.
- 삽입, 갱신, 삭제 등의 DML(Data Manipulation Language) 문장을 실행하는 경우, INSERT/UPDATE/DELETE 후 Connection 객체의 commit() 메서드를 사용하여 데이타를 확정 갱신한다.
- Connection 객체의 close() 메서드를 사용하여 DB 연결을 닫는다.
▼한국인을 위한 요약
방법을 간단히 요약하자면,
1) 오라클 connection 연결
2) connection이 cursor 객체 가져옴(연결도구)
3) cursor 객체의 fetch메서드를 이용해서 데이터를 서버로부터 가져온다.
4) cursor 객체의 execute() 메서드를 사용해서 파이썬에 입력한 SQL 문장을 오라클 DB 서버로 보낸다.
5) 주고받는 것이 완료되면 connection 객체의 commit() 메서드를 사용해서 데이터를 확정한다.
6) connection.close()를 해서 오라클과 연결을 끊는다.
즉, 정리하자면
오라클 수입 : import cx_Oracle as ora
오라클 Connection 연결 : conn = ora.connect('kosmorpa/test00@192.168.0.122:1522/orcl')
Cursor 불러오기 : cursor = conn.cursor()
a) SQL 입력문장 -> 오라클 DB : cursor.execute( 전송할 sql 문장 )
b) 오라클 DB 데이터 -> 파이썬 : cursor.fetch*****()
Cursor 닫기 : cursor.close()
오라클 DB 저장 : conn.commit()
오라클 연결 끊기 : conn.close()
이걸 이용해서 파이참(PyCharm)에서 DB를 원래 했던 sqlite가 아닌 윈도우에 설치 되어있는 오라클과 연동해서 해보도록 하자.
1. 입력처리
1) 디장고에서 폼으로 작성할 것
#디장고에서 폼으로 작성할 것
writev = input('작성자 : ')
pwdv = input('비밀번호 : ')
subjectv = input('제목 : ')
contentv= input('내용 : ')2) 입력해주고 insert 하는 sql문을 실행해준다.
#SQL문 작성
sql_insert ='insert into board values(board_seq.nextVal,:pwd,:write,:subject,:content,sysdate)'
sql_insert#입력값을 쿼리에 바인딩한 후 전송
cursor.execute(sql_insert,pwd=pwdv,write=writev,subject=subjectv,content=contentv)
#커서 닫고 commit 해준다.
cursor.close()
conn.commit()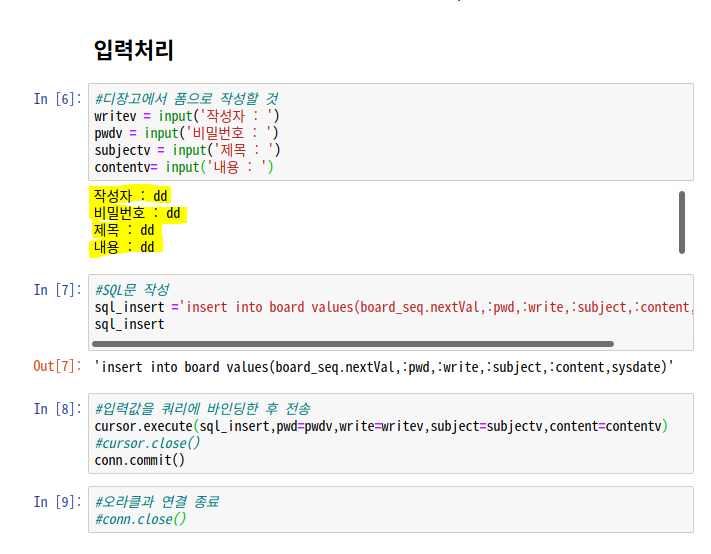
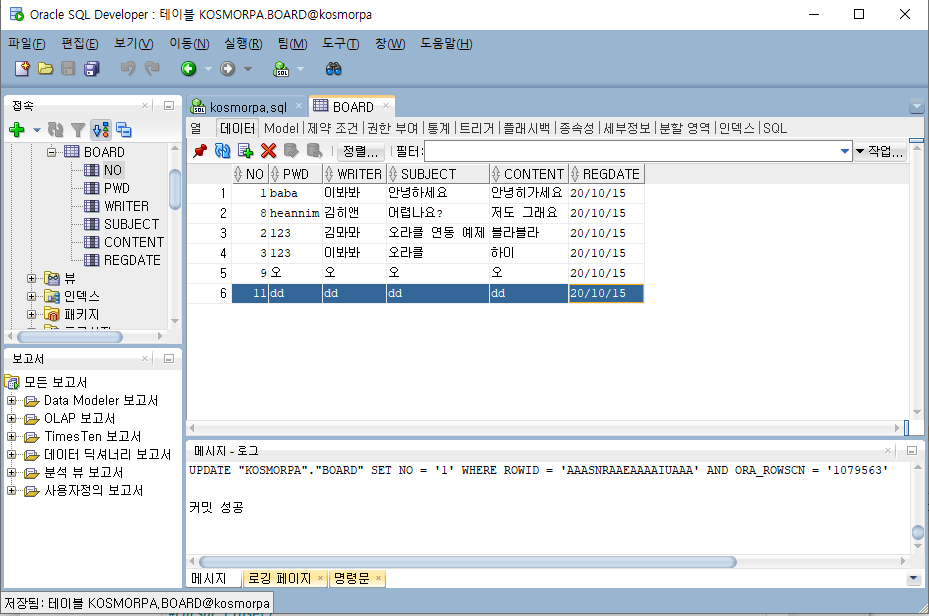
3) 오라클에 데이터가 잘 들어간 것을 볼 수 있다.
4) 오라클과 연결을 종료할 때. 하지만 지금은 닫지 않는다.
#오라클과 연결 종료
conn.close()
2. 출력
1) 변수 지정
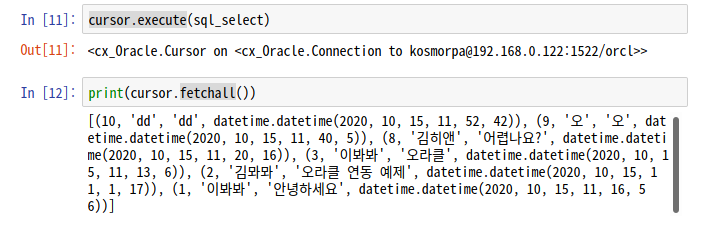
sql_select = 'select no,writer,subject,regdate from board order by 1 desc'
cursor.execute(sql_select)Cursor 객체의 execute() 메서드를 사용하여 SQL 문장을 DB 서버에 전송
2) 데이터를 서버로부터 가져온다.
print(cursor.fetchall())
3) 출력 완료 후 닫는다.
cursor.close()
conn.close()
3. 상세보기 구현
번호를 입력받아서 사용자의 정보를 모두 출력해보자.
fetchone() 사용해서 적용하기
#findone() : mybastis select_one()
nov = input("상세보기 값 : ")
sql_no = "select no,writer,subject,content,\
to_char(regdate,'yyyy-mm-dd') regdate from board where no=:no"
cursor = conn.cursor()
print(cursor)
cursor.execute(sql_no,no=nov)
print(cursor.fetchone())
4. 최근 글 5개만 출력하기(select)
#함수로 정의
def connections():
try:
conn= ora.connect('kosmorpa/test00@192.168.0.122:1522/orcl')
cursor = conn.cursor()
except Exception as e:
msg="예외발생"
print(msg)
return conn#최근 글 5개만 출력 fetchmany
def myFetchmany():
conn = connections()
cursor = conn.cursor()
sql_select = 'select * from board order by 1 desc'
cursor.execute(sql_select)
numRows = 5
res = cursor.fetchmany(numRows = numRows)
print('fetchmany {}'.format(numRows))
cursor.close()
conn.close()
return res
print(myFetchmany())
cf ) 서브쿼리를 이용해서 동일한 결과를 가져올 수 있다.(rowNum)
# 서브쿼리 사용해서 최근 5개만 추출해보기(위에 fetchmany와 동일하다.)
def examSelect():
conn = connections()
sql_select = "select no,writer,content,regdate from\
(select rownum,no,writer,content,regdate from\
(select * from board order by 1 desc) where rownum <=5)"
cursor = conn.cursor()
cursor.execute(sql_select)
rs = cursor.fetchall()
return rsselectList = examSelect()
selectList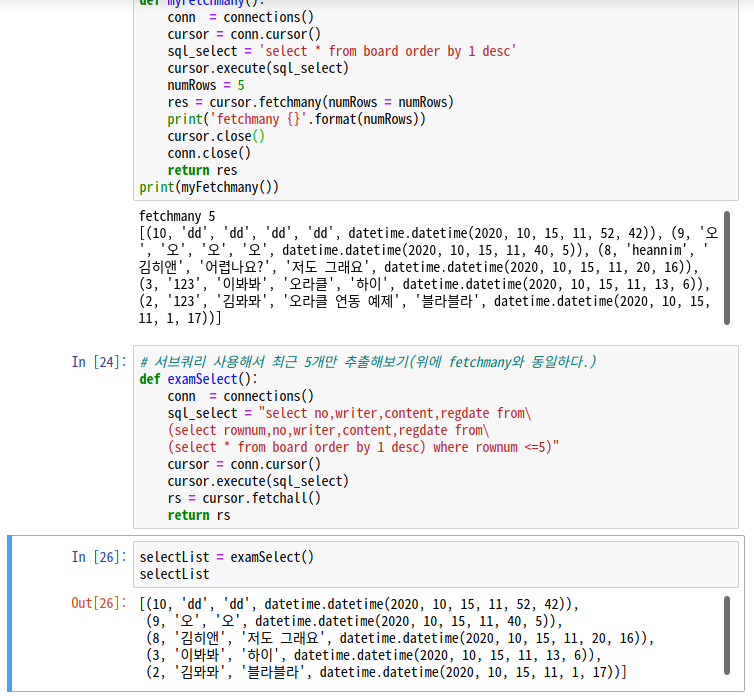
5. 삭제
#삭제 - insert, delete ,update
def boardDel(num):
conn = connections()
cursor = conn.cursor()
sql_delete = 'delete from board where no = :no'
try:
cursor.execute(sql_delete, no=num)
conn.commit()
except Exeption as e:
print(e)
finally:
conn.close()
num = input('삭제번호 :')
boardDel(num)
examSelect()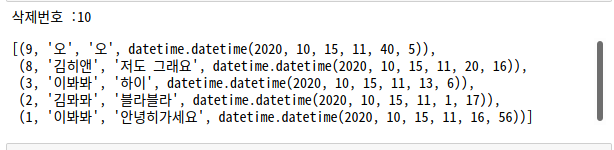
1. 카페에서 파일 다운로드(리눅스에서 다운받기)
2. 파이참에서 web1 이라는 앱 만들기
python manage.py startapp web13. templates>web1 > 파일 폴더 만들기
4. 다운받은 파일 홈 디렉토리로 옮겨버리고 압축을 풀자
mv base.html ~
mv static.zip ~
cd ~
unzip static.zip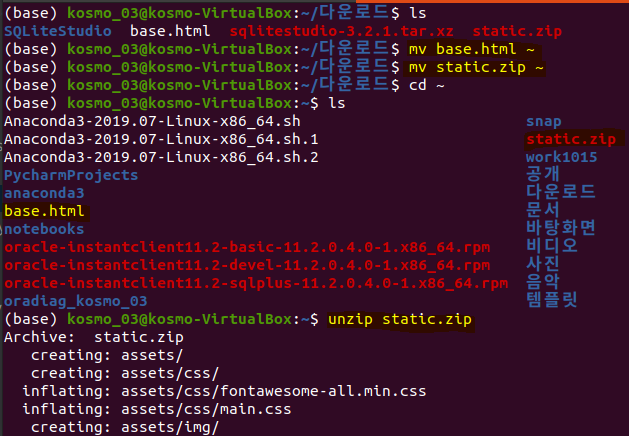
5. 홈에 푼 파일들을 다시 우리 프로젝트 환경에 templates에 옮겨줘야한다.
mv base.html PycharmProjects/myapps/web1/templates/web1/static 안에는 assets라는 폴더가 들어있다. 다시 web1에 리소스 파일을 넣을 static에 넣어준 후 옮겨준다.
mv assets/ PycharmProjects/myapps/web1/templates/web1/static/
6. urls에 홈 경로, views에 렌더링 입력, config/setting 에 web1 등록, config/urls에 등록.
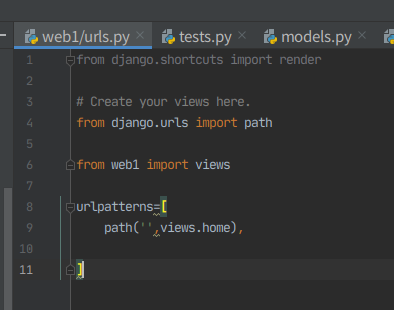
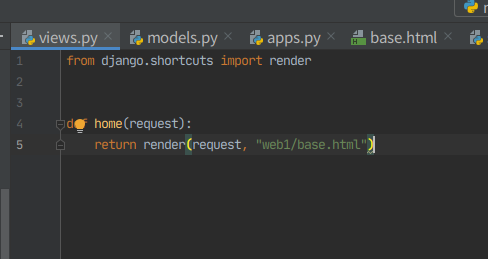
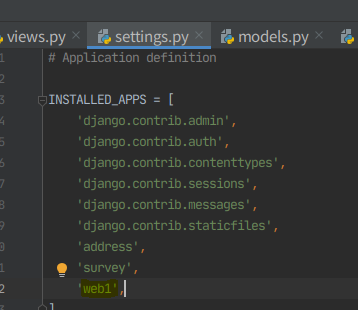
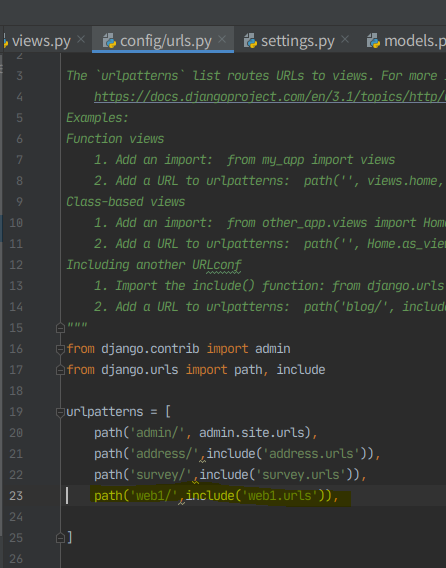
아직 DB를 안 건드렸으니까 admin과 마이그레이션은 안한다.
실행해보면,
python manage.py runserver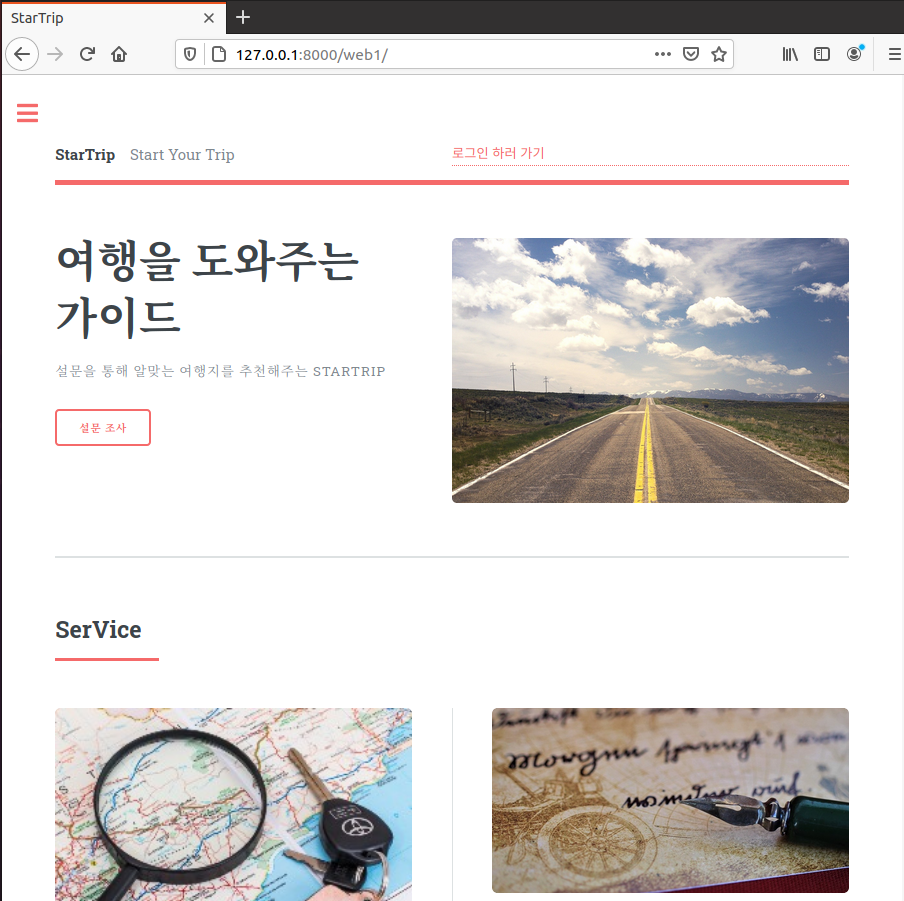
static에 모든 css와 js가 다 있어서 편했다.
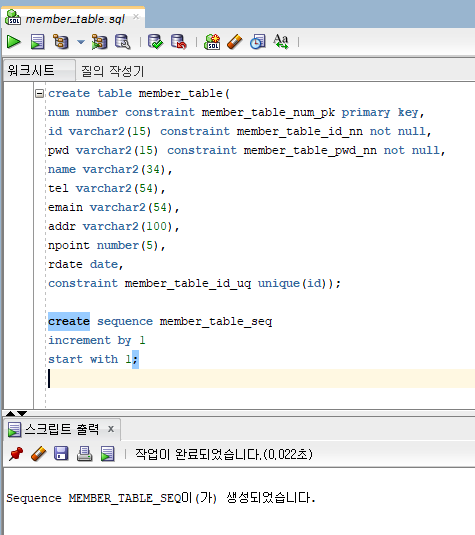
7. sql에 member_table 테이블 생성하기
create table member_table(
num number constraint member_table_num_pk primary key,
id varchar2(15) constraint member_table_id_nn not null,
pwd varchar2(15) constraint member_table_pwd_nn not null,
name varchar2(34),
tel varchar2(54),
emain varchar2(54),
addr varchar2(100),
npoint number(5),
rdate date,
constraint member_table_id_uq unique(id));
create sequence member_table_seq
increment by 1
start with 1;
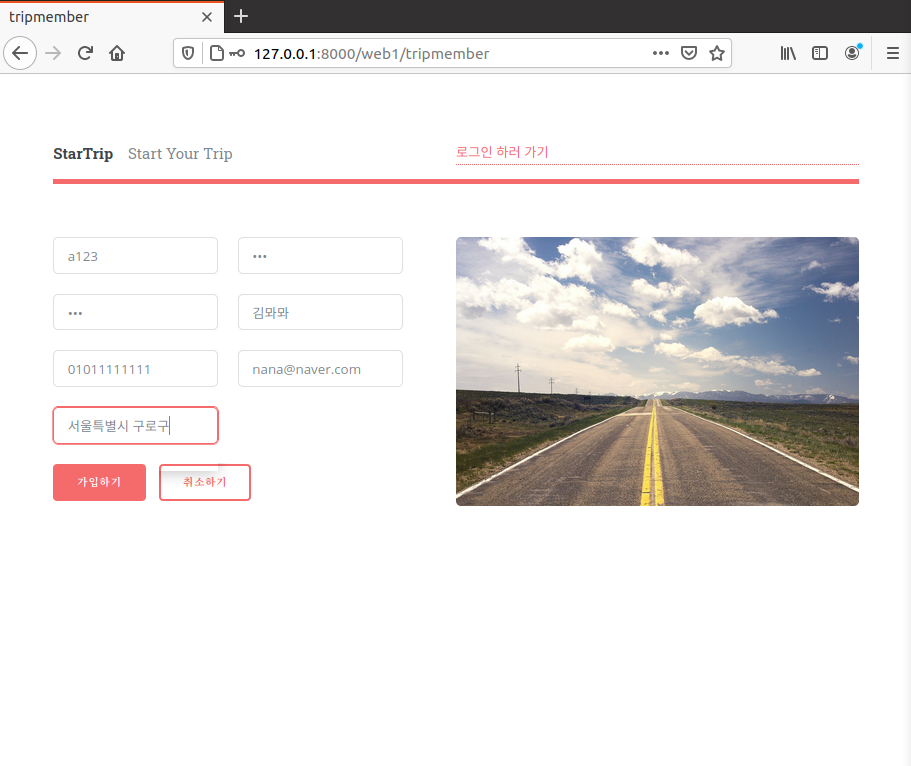
8. 이제 회원가입 페이지를 만들거다.
base.html의 내용을 복사해서 tripmember.html 만들기
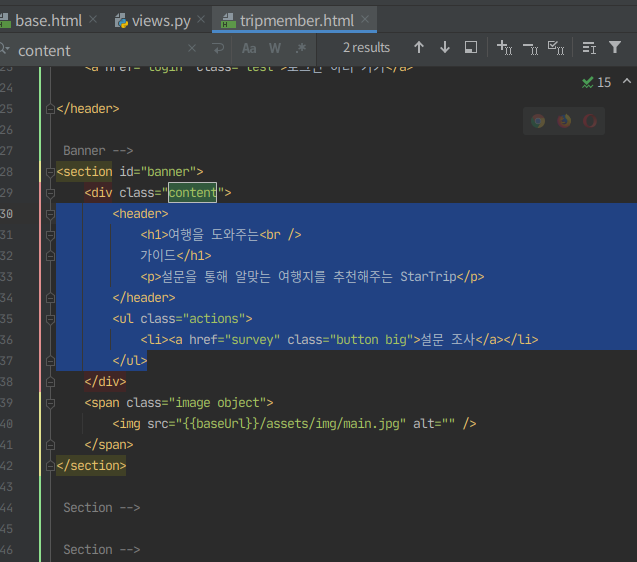
content 부분 변경하기 -> 회원가입 폼으로 변경할 것.
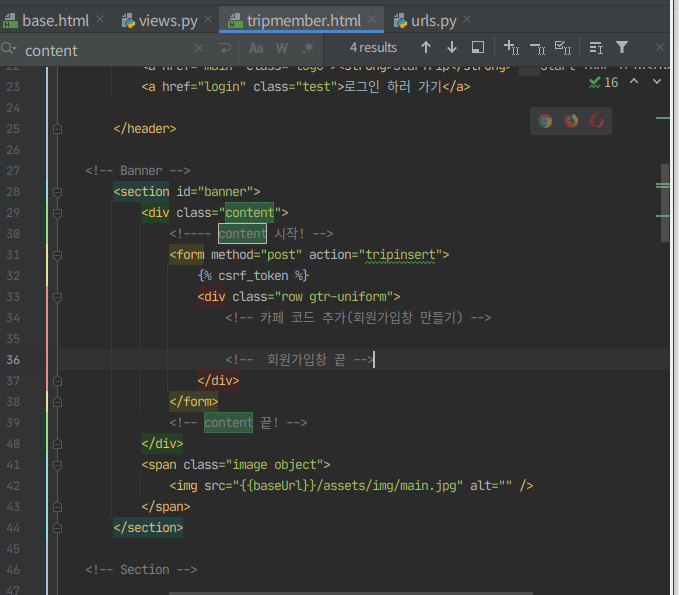
카페에 올라온 거 붙여넣고
<!-- Banner -->
<section id="banner">
<div class="content">
<!---- content 시작! -->
<form method="post" action="tripinsert">
{% csrf_token %}
<div class="row gtr-uniform">
<!-- 카페 코드 추가(회원가입창 만들기) -->
<div class="col-6 col-12-xsmall">
<input type="text" name="id" id="id" value="" placeholder="ID" />
</div>
<div class="col-6 col-12-xsmall">
<input type="password" name="pwd" id="pwd" value="" placeholder="비밀번호" />
</div>
<div class="col-6 col-12-xsmall">
<input type="password" name="chkpwd" id="chkpwd" value="" placeholder="비밀번호 확인" />
</div>
<div class="col-6 col-12-xsmall">
<input type="text" name="name" id="name" value="" placeholder="이름" />
</div>
<div class="col-6 col-12-xsmall">
<input type="tel" name="tel" id="tel" value="" placeholder="전화번호" />
</div>
<div class="col-6 col-12-xsmall">
<input type="email" name="email" id="email" value="" placeholder="Email" />
</div>
<div class="col-6 col-12-xsmall">
<input type="text" name="addr" id="addr" value="" placeholder="주소" />
</div>
<!-- Break -->
<div class="col-12">
<ul class="actions">
<li><input type="submit" value="가입하기" class="primary" /></li>
<li><input type="reset" value="취소하기" /></li>
</ul>
</div>
<!-- 회원가입창 끝 -->
</div>
</form>
<!-- content 끝! -->
</div>
<span class="image object">
<img src="{{baseUrl}}/assets/img/main.jpg" alt="" />
</span>
</section>
<!-- Banner 섹션 끝-->
<!-- Section 지움-->urls.py에 추가하기
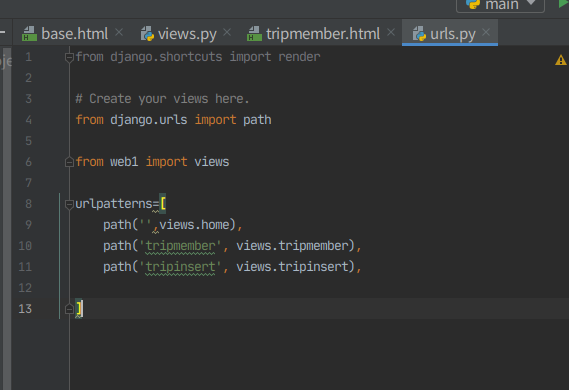
views 추가
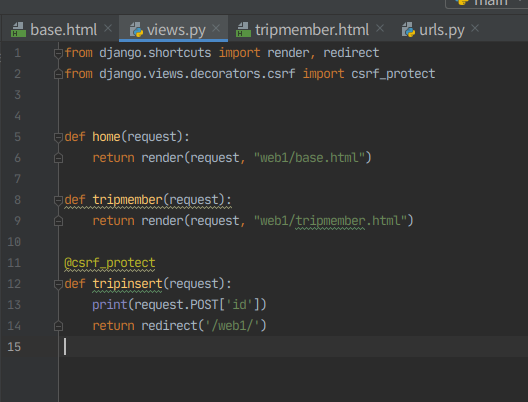
섹션부분 전부 지우기(깔끔하게)
9. models 가자.
오라클로 연결하면 자동으로 마이그레이션이 생기지 않는다. 따라서 아까 주피터에서 했던 것 처럼 데이터를 불러오자.
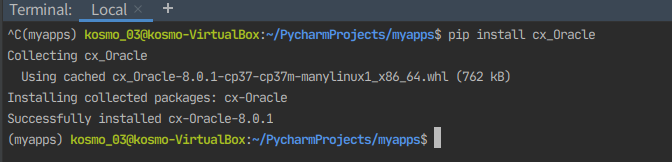
여기는 base가 아니라 myapp이기 때문에 cx_Oracle를 다시 받아줘야한다. 잠시 서버 멈추고 다운 받고 해보자
pip install cx_Oracle
10. 아까 주피터에서 했던 것처럼 가져오자.
모델에 작성하기
예외있으면 예외발생 메시지 나오게 하자.
from django.db import models
import cx_Oracle as ora
# Create your models here.
def connections():
try:
conn= ora.connect('kosmorpa/test00@192.168.0.122:1522/orcl')
except Exception as e:
msg="예외발생"
print(msg)
return conn
def memberinsert(addr_list):
print(addr_list)
conn=connections()
cursor=conn.cursor()
sql="insert into member_table values(member_table_seq.nextVal,:1,:2,:3,:4,:5,:6,0,sysdate)"
cursor.execute(sql,addr_list)
cursor.close()
conn.commit()
conn.close()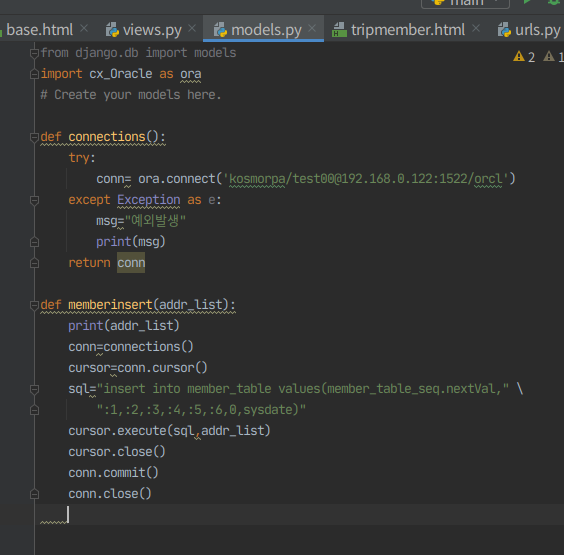
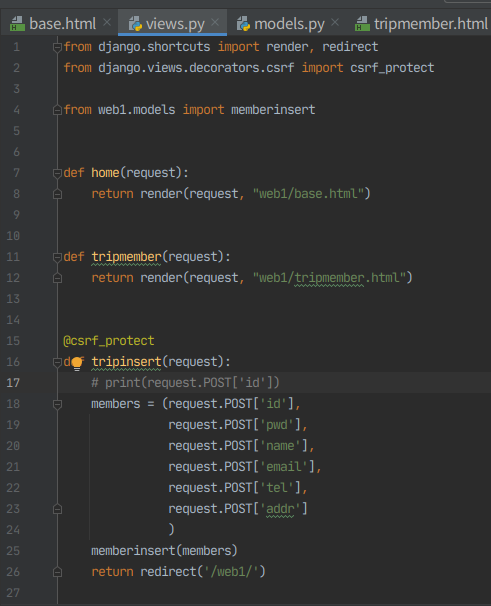
11. view 수정
from django.shortcuts import render, redirect
from django.views.decorators.csrf import csrf_protect
from web1.models import memberinsert
def home(request):
return render(request, "web1/base.html")
def tripmember(request):
return render(request, "web1/tripmember.html")
@csrf_protect
def tripinsert(request):
#print(request.POST['id'])
members = (request.POST['id'],
request.POST['pwd'],
request.POST['name'],
request.POST['email'],
request.POST['tel'],
request.POST['addr']
)
memberinsert(members)
return redirect('/web1/')
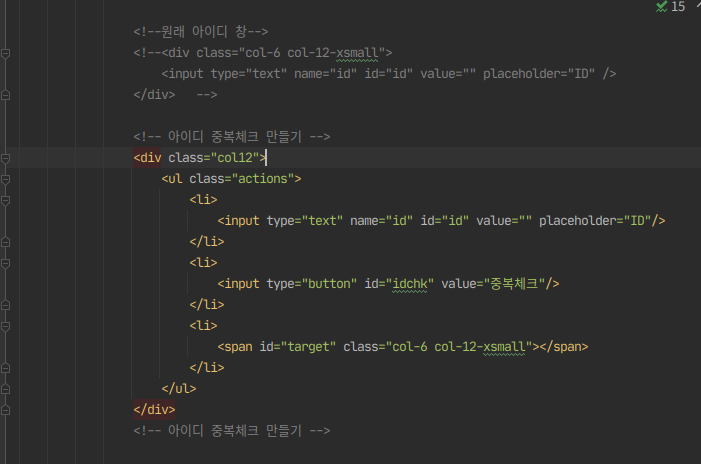
12. 회원가입 창에 아이디 중복 체크 만들기
버튼은 따로 만들어주심
<div class="col12">
<ul class="actions">
<li>
<input type="text" name="id" id="id" value="" placeholder="ID"/>
</li>
<li>
<input type="button" id="idchk" value="중복체크"/>
</li>
<li>
<span id="target" class="col-6 col-12-xsmall">ㅇㅇ</span>
</li>
</ul>
</div>이걸 아까 있던 id 자리에 바꿔넣는다.
'[ 빅데이터 ]' 카테고리의 다른 글
| [빅데이터] 홈페이지 만들기(3) : 파이썬으로 파일 업로드 앱 만들기(cnn, 이미지분류) (1) | 2020.10.17 |
|---|---|
| [빅데이터] 홈페이지 만들기(2) : 파이썬으로 로그인/로그아웃 데모 앱 만들기(오라클 연동) (0) | 2020.10.16 |
| [ 빅데이터 ] c3js - 분석 결과 시각화하기, 파이차트 출력하기 (0) | 2020.10.14 |
| [빅데이터] 리눅스 / 디장고(Django) 오라클 11g 설치, 연동 (0) | 2020.10.14 |
| [빅데이터] 설문조사 앱 만들기(pycharm, Django) (1) | 2020.10.14 |