[ 파이썬 스레딩 모듈을 사용해서 데이터 스크랩핑하기 ]
find / find_all / select / select_one
1. css 선택자 사용해서 크롤링하기 : select() 메소드
BeautifulSoup이 제공하는 여러 가지 유용한 기능 중, CSS 선택자를 매개변수로 받는 select() 메서드를 사용해보자.
from bs4 import BeautifulSoup
html = """
<html>
<body>
<div>test</div>
<div id='main'>
<h1>도서 목록</h1>
<ul class ='items'>
<li>자바 입문</li>
<li>HTML</li>
<li>PYTHON</li>
</ul>
</div>
</body>
</html>
"""
soup = BeautifulSoup(html,"html.parser")
도서 목록을 가져오고 싶다.
도서목록은 <div> 태그의 자식인 <h1> 태그 안에 있다.
<div>의 id가 'main'이다. main의 자식 > h1을 가져오기 : select_one, select
h1 = soup.select_one('div#main > h1').string
print('h1 => ', h1)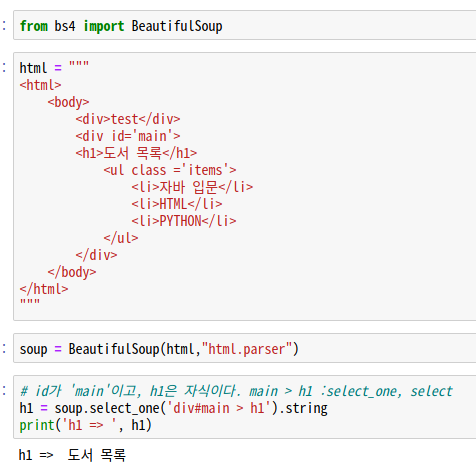
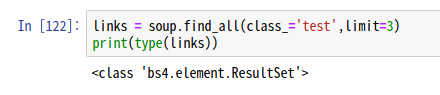
find처럼 select도 여러개를 가져오면 list로 들어온다.
리스트를 for문으로 쪼개보자.
# div#main > ul.items >li
li_list = soup.select('div#main > ul.items >li') #리스트로 반환
print(li_list, ":", type(li_list))
#쪼개기
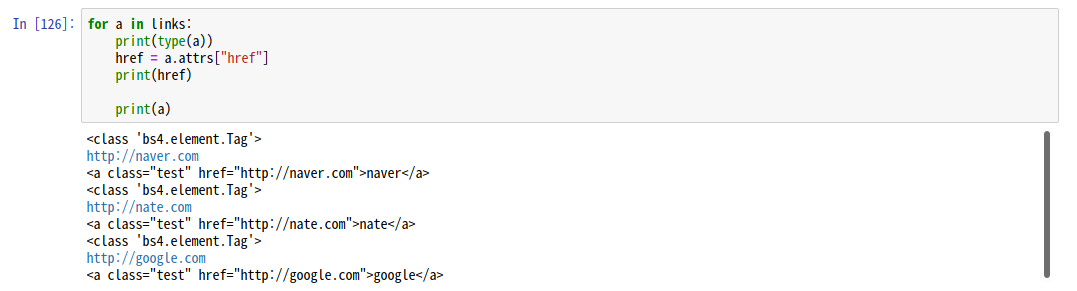
for li in li_list:
print('li = ',li.string)
2. 네이버 금융에서 시장 지표 크롤링하기
1) url 지정
# 네이버금융 > 시장 지표에 특정 값을 수집하기
import urllib.request as req
url = 'https://finance.naver.com/marketindex/'
2) url 열기
# stream 통해서 페이지 값 얻기
res = req.urlopen(url)
print(res)
3) 파싱하기
soup = BeautifulSoup(res,'html.parser')
soup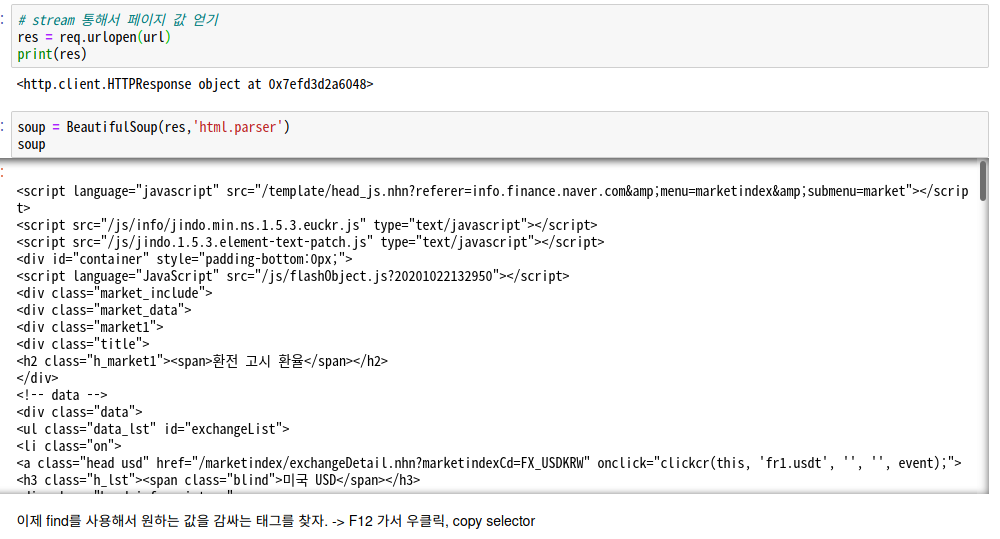
4) F12로 selector 복사 후 select_one으로 값 크롤링하기
text,string 전부 가능하다.
#선택자 : exchangeList > li.on > a.head.usd > div > span.value
price = soup.select_one('#exchangeList > li.on > a.head.usd > div > span.value')
print(price.text, price.get_text(), price.string)
5) 각국의 환율정보를 전부 출력하면?
title =soup.select('a.head >h3:nth-child(1) > span')
value =soup.select('div:nth-child(2) > span.value')
cont =zip(title,value)
for t,v in cont:
print('제목: ',t.string,' , 환율: ',v.string) 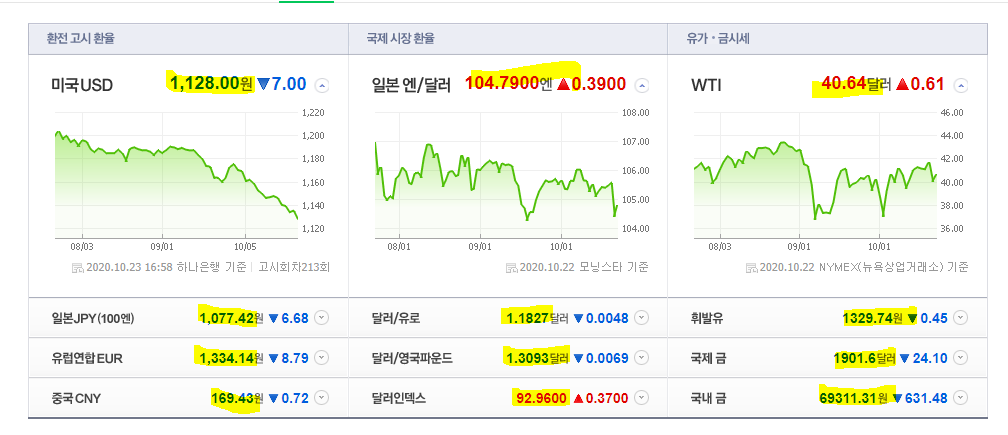

3. 위키피디아 크롤링
수록 시 목록을 크롤링해보자.
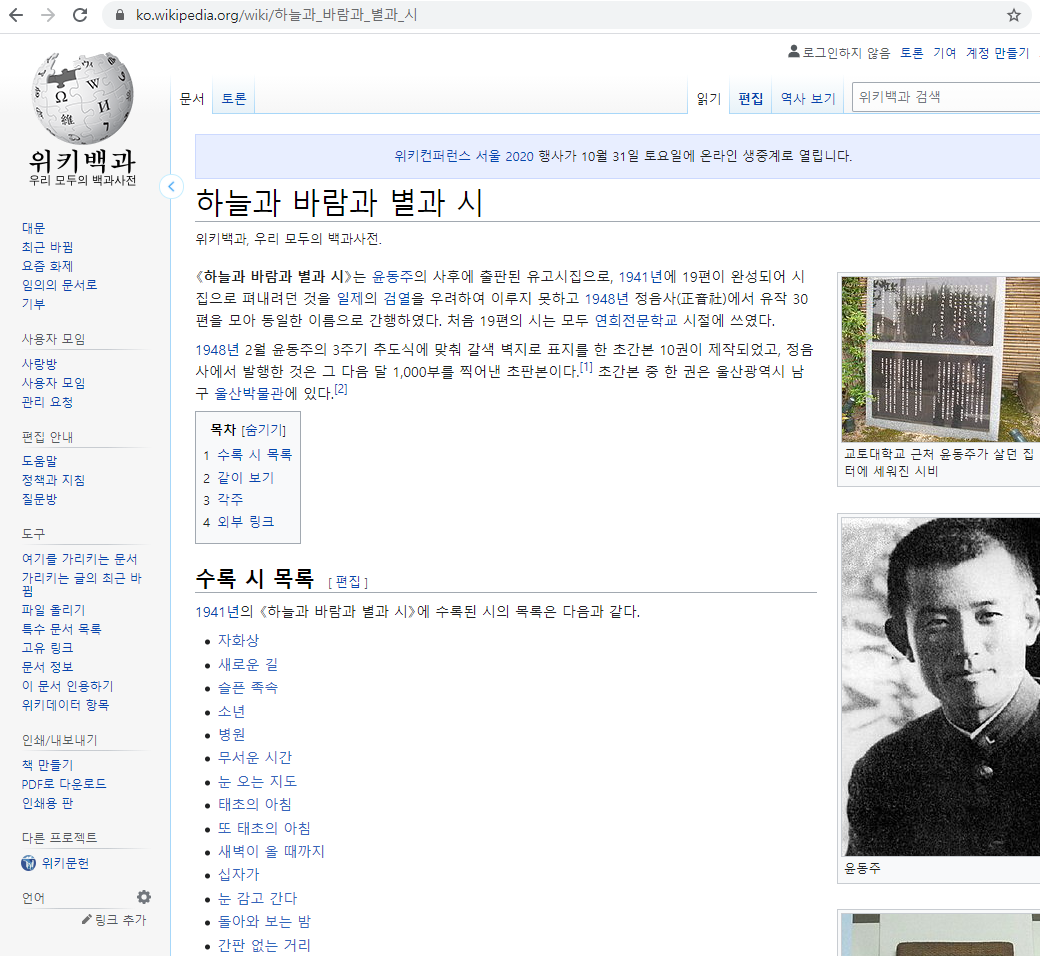
# select 출력
import urllib.request as req
url = 'https://ko.wikipedia.org/wiki/%ED%95%98%EB%8A%98%EA%B3%BC_%EB%B0%94%EB%9E%8C%EA%B3%BC_%EB%B3%84%EA%B3%BC_%EC%8B%9C'
res = req.urlopen(url)
soup=BeautifulSoup(res,"html.parser")
lista = soup.select('#mw-content-text > div.mw-parser-output > ul:nth-child(9) > li:nth-child(19) > a')
lista
#선택되어있는 객체가 19이기 때문에 전부 가져오려면 li만 가져오면 된다.
listb = soup.select('#mw-content-text > div.mw-parser-output > ul:nth-child(9) > li > a')
listb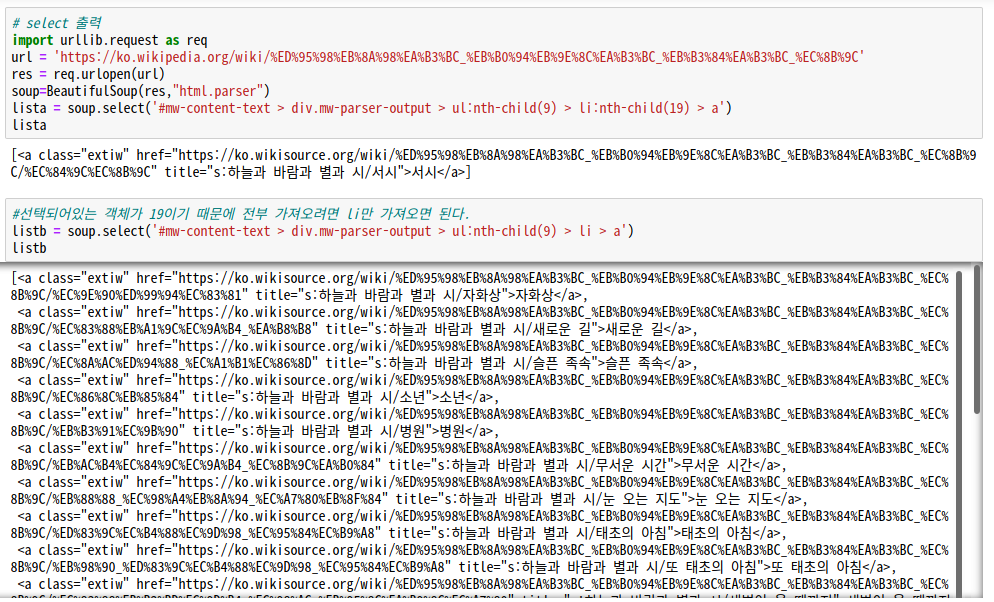
# lista
for a in lista:
print(a.string)
# listb
for b in listb:
print(b.string)
4. 속성별로 크롤링해오기
문자에 칠해진 색깔대로 크롤링해보자.

from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen('http://www.pythonscraping.com/pages/warandpeace.html')
bs = BeautifulSoup(html, 'html.parser')
#선택되어있는 객체가 19이기 때문에 전부 가져오려면 span 가져오면 된다.
ab = bs.findAll('span',{"class":"green"})
for qq in ab:
print(qq.get_text()) #태그 내부의 텍스트 출력
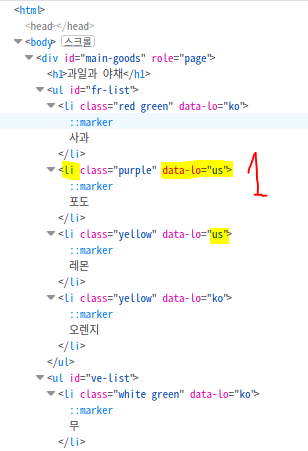
5. 같은 태그 중 n번째 요소 크롤링하기
여기서 연근만 불러와보자.
▽ 파일 다운로드

from bs4 import BeautifulSoup
fp = open('fruits-vegetables.html',encoding='utf-8')
soup = BeautifulSoup(fp,"html.parser")
#CSS 선택자로 추출하기 : li:nth-child(n) : li 요소 중에서 n번째 요소를 선택
ss = soup.select('li')
ss파일 경로를 입력하고 open()으로 파일을 읽어보자.(인코딩 필수)

연근은 야채 중 5번째로 위치해 있다.

print(soup.select_one("li:nth-child(5)").string)
print(soup.select_one("li:nth-of-type(5)").string) #위와 동일
- 인덱스 번호를 이용해서 select 하는 방법은 다양하다. 속성을 다양하게 둘 수도 있고, 인덱스번호를 설정 해 줄 수도 있다.



- find로 찾을 경우.

6. GDP 순위 크롤링해서 table로 출력하기(pandas)
1) table 크롤링하기

from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen('https://worldpopulationreview.com/countries/countries-by-gdp')
# 파싱
bs = BeautifulSoup(html, 'html.parser')
# tbody 태그의 클래스 크롤링
ab = bs.findAll('tbody',{"class":"jsx-2642336383"})
# 반복문으로 리스트 분해
for qq in ab:
print(qq.get_text())텍스트가 정신없이 크롤링되었다.

2) 컬럼별로 차례대로 나열하기
저렇게 보면 아무도 못알아본다. 컬럼과 내용을 섞어서 이쁘게 나열해주자.
from urllib.request import urlopen
from bs4 import BeautifulSoup
import gzip
url='https://worldpopulationreview.com/countries/countries-by-gdp'
res = req.urlopen(url)
soup = BeautifulSoup(res,'html.parser')
#각 카테고리별로 크롤링해주기
rank=soup.select('#asiaCountries > div:nth-child(1) > div:nth-child(1) > div:nth-child(1) > div:nth-child(1) > div:nth-child(2) > div:nth-child(2) > table:nth-child(1) > tbody:nth-child(2) > tr > td:nth-child(1)')
name=soup.select('#asiaCountries > div:nth-child(1) > div:nth-child(1) > div:nth-child(1) > div:nth-child(1) > div:nth-child(2) > div:nth-child(2) > table:nth-child(1) > tbody:nth-child(2) > tr > td:nth-child(2) > a')
GDP_imp=soup.select('#asiaCountries > div:nth-child(1) > div:nth-child(1) > div:nth-child(1) > div:nth-child(1) > div:nth-child(2) > div:nth-child(2) > table:nth-child(1) > tbody:nth-child(2) > tr > td:nth-child(3)')
GDP_un=soup.select('#asiaCountries > div:nth-child(1) > div:nth-child(1) > div:nth-child(1) > div:nth-child(1) > div:nth-child(2) > div:nth-child(2) > table:nth-child(1) > tbody:nth-child(2) > tr > td:nth-child(4)')
GDP_per=soup.select('#asiaCountries > div:nth-child(1) > div:nth-child(1) > div:nth-child(1) > div:nth-child(1) > div:nth-child(2) > div:nth-child(2) > table:nth-child(1) > tbody:nth-child(2) > tr > td:nth-child(5)')
population=soup.select('#asiaCountries > div:nth-child(1) > div:nth-child(1) > div:nth-child(1) > div:nth-child(1) > div:nth-child(2) > div:nth-child(2) > table:nth-child(1) > tbody:nth-child(2) > tr > td:nth-child(6)')
#all에 묶어버리자
all=zip(rank,name,GDP_imp,GDP_un,GDP_per,population)
#리스트로 분리
for a,b,c,d,e,f in all:
print('순위:',a.text,"*",'나라:',b.text,"*",'GDP_imp:',c.text,"*",'GDP_un:',d.text,"*",'GDP_per:',e.text,"*",'인구:',f.text) 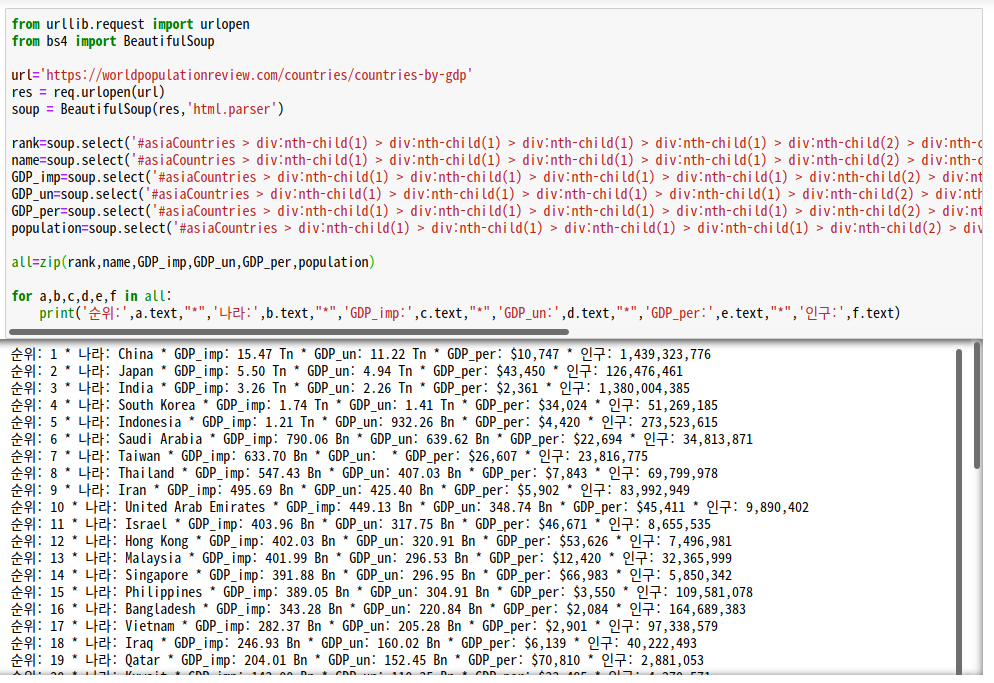
가져올 때 .클래스명 또는 #id명 으로 가져오면 더 편하다.
text=soup.select('tbody.jsx-2642336383 td') #tbody 태그의 jsx~클래스 중, td만 가져와라
for a in text:
print(a.string)짦은 코딩으로 동일한 결과를 가져온다.
▼선생님 답안
from bs4 import BeautifulSoup
import urllib.request as req
import gzip
url='https://worldpopulationreview.com/countries/countries-by-gdp'
res = req.urlopen(url)
contents = res.read()
soup = BeautifulSoup(contents,'html.parser')
htmltable2 = soup.find('table',{'class':'jsx-1487038798 table table-striped tp-table-body'})
print(type(htmltable2)) => <class 'bs4.element.Tag'>
theads = htmltable2.find_all('thead')
for tr in theads:
listv=[th.get_text(strip=True) for th in tr.find_all('th')]
print(listv)
⭐결과⭐:
['Rank', 'Name', "GDP (IMF '19)", "GDP (UN '16)", 'GDP Per Capita', '2019 Population']파싱까지의 과정은 동일하다.
그 후 table 태그에서 class 가 'jsx-1487038798 table table-striped tp-table-body'인 값을 찾아 htmltable2에 저장한다.
이 htmltable2의 type은 class 이다.
htmltable2 에서 'thead' 태그를 모두 찾아 theads 라는 변수에 저장한다.
theads의 길이만큼 반복문을 돌려 listv라는 변수를 생성한다. 여기서 theads의 길이는 1이다. ㅇㅇ 리스트에 딱 한 개 저장되어있음.
그럼 listv 라는 리스트 변수 안에는 th 태그의 텍스트 값이 모두 저장된다.
th의 값은 어떻게 찾았느냐!
listv 안에 준 반복문을 살펴보자 - for th in tr.find_all('th')
theads에서 th를 찾고 그 th의 길이(갯수)만큼 반복문이 돈다.
위에 올라가서 thead 태그 안에 th 태그를 세어보면 여섯개 있다.
일단 위 코딩으로 타이틀 명을 전부 추출 하였다.
[출처]
이렇게 나열하는 것들을 pandas를 이용하면 dataframe에 넣을 수 있다.
csv나 excel, Json을 읽어오는 기능을 한다. -> pandas는 표, 행렬
또는 이렇게 수집된 Dataframe을 배열로 바꿀 수 있음 -> 넘파이(numpy)
3) 테이블을 컬럼과 내용으로 분리해서 가져오기
테이블은 컬럼과 하단 리스트로 되어있다. 다행히 여기서는 <thead>와 <tbody>가 나뉘어있었다.
- 내용부터 크롤링하자.
#테이블 전체 크롤링
htmltable2 = soup.find('table',{'class':"jsx-1487038798 table table-striped tp-table-body"})
print(type(htmltable2))
# 전체 중 내용에 해당하는 tr만 크롤링
trs =htmltable2.find_all('tr')
trs
#tr 리스트 분리하기
for tr in trs:
listz = [td.get_text(strip=True) for td in tr.find_all('td')]
print(listz)
- 컬럼 크롤링하기
# 컬럼 가져오기
theads = htmltable2.find_all('thead')
theads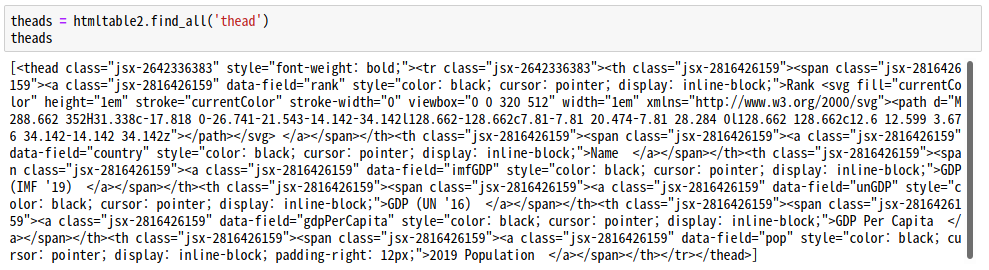
#리스트 쪼개기
for tr in theads:
listv = [th.get_text(strip=True) for th in tr.find_all('th')]
print(listv)
- 컬럼과 내용을 합친 list를 생성한다.
rows = [] #list를 선언 및 생성
idx = 0
for tr in trs:
if idx ==0:
rows.append(listv)
else:
rows.append([td.get_text(strip=True) for td in tr.find_all('td')])
idx = idx +1
rows
4) pandas 이용해서 테이블로 만들기
import pandas as pd
df = pd.DataFrame(rows[1:], columns=rows[0])
df #테이블로 출력된다. 1번인거는 컬럼이 0번이기 때문에
7. pdf 읽어 오기
1) pdfminer3k 설치하기
!pip install pdfminer3k2) 필요한 기능 수입하기
from pdfminer.pdfinterp import PDFResourceManager, process_pdf
from pdfminer.converter import TextConverter #PDF를 읽어와서 텍스트로 converter 헤주는 녀석
from pdfminer.layout import LAParams #파라미터 객체
from io import StringIO
from io import open
from urllib.request import urlopen
3)pdf를 읽기 위한 기능 정의하고 url 입력하기
def readPDF(pdfFile):
#리소스 매니저를 생성
rsrcmgr = PDFResourceManager()
#PDF 내부의 텍스트를 입출력하기 위한 StringIo객체를 생성
restr = StringIO()
#파라미터 객체
laparams = LAParams()
#pdf 내용을 텍스트로 변환하기 위해서 객체를 생성
#textConverter(매니저, IO, layoutParam)
device = TextConverter(rsrcmgr, restr,laparams=laparams)
#PDF Process가 실제로 변환된 값 -> text로 바꾸기
#pricess_pdf(매니저, textConverter, 읽을 pdf 파일)
process_pdf(rsrcmgr,device,pdfFile)
device.close()
#Io를 통해서 값을 content란 변수에 읽어와서 저장한다.
content = restr.getvalue()
restr.close()
return content
#url 수입
from urllib.request import urlopen,Request
urlv = 'https://buildmedia.readthedocs.org/media/pdf/beautiful-soup-4/latest/beautiful-soup-4.pdf'
4) url 읽고 text로 출력하기
req = Request(urlv, headers={'User-Agent': 'Mozilla/5.0'})
pdfFlie = urlopen(req)
outputString = readPDF(pdfFlie)
print(outputString)
5) text파일로 저장하기
with open('readPDF1.txt','w') as f:
f.write(outputString)
print('Save !')
[ with ]
파일을 다루는 처리를 할때는 필수적으로 파일 오픈(open) 파일 닫기(close) 과정을 거치게 됩니다.
하지만 코드가 복잡해지면서 개발자는 파일을 열어놓고 닫지 않는 실수를 할 경우가 생기게 됩니다.
with ... as 구문을 사용하게 되면 파일을 열고 해당 구문이 끝나면 자동으로 닫히게 되어서
(close를 안써도) 이러한 실수를 줄일 수 있습니다.(출처)
open 함수는 다음과 같이 "파일 이름"과 "파일 열기 모드"를 입력값으로 받고 결괏값으로 파일 객체를 돌려준다.
우리가 write 메서드에 outputString 이라는 변수를 던져주면 그 변수 안에 들어 있는 데이터를 써서 'readPDF1.txt'라는 파일을 생성하여 저장해준다. (다다님께 영광을...!!)
8. 네이버 영화 평점 크롤링하기
## 필요한 모듈들 수입하기
import requests
import threading, time
from bs4 import BeautifulSoup
import pandas as pd
import math
url='https://movie.naver.com/movie/bi/mi/pointWriteFormList.nhn?code=188909&type=after&isActualPointWriteExecute=false&isMileageSubscriptionAlready=false&isMileageSubscriptionReject=false&page={}'
# url 뒤에 {}에 넣을 인자 설정. url의 2번째를 넣는다.(페이지 번호)
response = requests.get(url.format(1))
# response를 텍스트로 파싱하기
soup = BeautifulSoup(response.text,'html.parser')
#코멘트를 찾는 함수 정의
def find_comment(page=1):
response = requests.get(url.format(page))
soup = BeautifulSoup(response.text,'html.parser')
#class가 'score_result'인 div 태그를 찾아 넣기
tag = soup.find("div", class_='score_result')
#태그 중 li만 다 찾기 -> 코멘트
tagli = tag.find_all("li")
#점수와 리뷰를 담을 list 선언
score, text = [], []
for e in tagli: #8점 이상이면 리스트의 1번 인덱스에 추가
if int(e.em.text)>= 8:
score.append(1)
text.append(e.p.get_text("", strip=True))
elif int(e.em.text)<=5: #5점 이하면 리스트의 0번 인덱스에 추가
score.append(0)
text.append(e.p.get_text("", strip=True))
return score,textdef searchNaver(totalPage):
import time
sv, tv= [], []
for i in range(1, 1753):
time.sleep(0.1) #시간 간격을 두고 다운로드를 받아야 한다.
print("Count:", i, end="\r") # 카운트 올라가는거 표시(없어도 됨)
s, t = find_comment(i)#위에서 정의한 find_comment에 i값을 넣어서 카운트
sv += s
tv += t #누적하면서 계속 카운트
df = pd.DataFrame([sv, tv]).T #df 양식중에 하나. 행과 열을 전치시킨다.
df.columns = ['score','text'] #컬럼명 설정
df.to_csv('comment.csv') # csv로 저장
t1 = threading.Thread(target=searchNaver,args=(1753,)) # 스레드로 데이터 전송
t1.start()
print("TestCode!")
▼ thread?
'[ 빅데이터 ]' 카테고리의 다른 글
| [빅데이터] spring MVC (0) | 2020.10.30 |
|---|---|
| [빅데이터] 리눅스 / Selenium 설치 및 사용법 (0) | 2020.10.23 |
| [빅데이터] 웹 크롤링 : BeautifulSoup(1) find, xml 파싱, 태그 속성값 크롤링 (0) | 2020.10.23 |
| [빅데이터] 프로젝트 - 상품등록 페이지 만들기(2) (0) | 2020.10.20 |
| [빅데이터] 프로젝트 - 상품등록 페이지 만들기(1) (0) | 2020.10.19 |