Pandas
온전히 통계 분석을 위해 고안된 R 과는 다르게 python은 일반적인 프로그래밍 언어(general purpose programming language) 이며, 데이터 분석을 하기 위해서는 여러가지 라이브러리를 사용할 수 밖에 없다. 이 패키지들 중 R의 dataframe 데이터 타입을 참고하여 만든 것이 바로 pandas dataframe이다. pandas는 dataframe을 주로 다루기 위한 라이브러리이며, dataframe을 자유롭게 가공하는 것은 데이터 과학자들에게 중요하다.(출처)
모양은 엑셀 시트를 하나의 데이터 타입으로 만들어 놓은 듯 하다. 행과 열로 이루어져 있어, 테이블의 형식으로 볼 수 있다.
DataFrame
Series들의 집합.
여러개의 Series(행)이 모여 하나의 테이블형식의 데이터를 생성할 수 있다.
행과 열이 있는 table 형태를 가진다.
Series
DataFrame의 한 컬럼 데이터세트.
Series 역시 DataFrame의 인덱스와 동일한 인덱스를 가진다.
Series는 테이블 형식의 데이터로 봤을때 하나의 레코드 즉, 행 값으로 생각하면 된다.
=> 즉, Series는 컬럼이 하나인 데이터 구조체이고, DataFrame은 컬럼이 여러개인 데이터 구조체이다.
자료구조
| 리스트 | 튜플 | 딕셔너리 |
| a=[1,2,3] | a= (1,2,3) | a={'kim' : 25, 'park' : 22, 'lee' : 34} a={ "a" : [5,6,7], "b" : [8,9,10]} |
1. 튜플(tuple)
- 리스트와 비교가 많이되며, 리스트와의 가장 큰 차이점은 요소를 삭제하거나 변경할 수 없다는 것. 이를 immutable(불변성) 이라고 표현함, iterable 함(반복 가능한 객체)
- 리스트는 append, remove 메소드로 요소들을 추가하거나 삭제할 수 있지만 튜플은 이러한 메소드가 없음
- 튜플 + 튜플 형식으로 요소를 추가할 수는 있으며, 삭제도 indexing을 통해서 삭제하고자 하는 요소의 index를 선택하지 않으면 가능하다. But, 이와 같은 방식은 억지로(?) append나 remove가 된 것 처럼 한 것이라 할 수 있음
- 리시트에서는 예를 들어 a라는 리스트가 있을 때, a 자체를 변화를 줄 수 있지만, 튜플은 a라는 튜플 b라는 튜플이 있을때 c = a + b 형식으로 새로운 변수에 할당하는 방식으로 append와 결과적으로만 동일한 튜플을 만들 수 있는 것이다.
- 또한, 다른 type의 데이터들을 담을 수 있음 ('a', 1, 3) 이런 식으로.
2. 리스트(list)
- 튜플과 비교가 많이되며, 튜플과의 가장 큰 차이점은 요소를 삭제하거나 변경할 수 있다는 것. 이를 mutable(가변성)이라고 표현함, iterable 함(반복 가능한 객체)
- 리스트는 append, remove 메소드로 요소들을 추가하거나 삭제할 수 있음
- 튜플과 마찬가지로 리스트 + 리스트 형식으로 요소를 추가할 수 있음
- 또한, 다른 type의 데이터들을 담을 수 있음 ['a', 1, 3] 이런 식으로.
3. 딕셔너리(dict)
- 딕셔너리를 구현한 클래스는 셋(set)
- 따라서, 딕셔너리는 셋처럼 중복이 불가능한 collection 자료형이고, mutable(가변성) 하며, key : value 라는 독특하고 유용한 구조로 이루어짐(중복이 불가능하다는 뜻은 key값들 끼리 중복이 불가능 하다는 뜻)
- a라는 딕셔너리가 있을때 keys나 values 메소드를 활용하여 key나 value값 확인가능. key와 value를 모두 확인하고 싶을 때는 items 메소드를 사용
- (참고) B = {'a' : [1]}라는 딕셔너리는 value가 list 형태이므로 B['a'].append or B['a'].remove 가 가능
4. 셋(set)
- 셋은 순서가 없는 중복이 불가능한 collection 자료형이다. -> 내장모듈 collections 알아두면 좋음. mutable(가변성) 함
- 요소들 간의 순서가 없음 -> 따라서, indexing이 불가 -> not iterable
- 중복제거 교집합, 합집합, 차집합 등의 수학적인 계산이 가능
- 셋은 add(요소 1개 추가), update(여러요소 추가), remove 메소드를 활용하여 요소를 추가/삭제한다.
- 합집합은 a | b로 표현, 차집합은 a - b로 표현, 교집합은 a & b로 표현
Series
# 자료구조 -> Series 생성 : pd.Series(자료구조)
# list -> Series로 바꾸기
a = pd.Series([22,23,44,55,28])
# dict -> Series로 바꾸기
a = pd.Series({'kim' : 25, 'park' : 22, 'lee' : 34})
# tuple -> Series로 바꾸기
a = pd.Series((10,20,30))
# 배열(Array)과 리스트(List) 차이
| Array | List |
| 여러 데이터를 하나의 이름으로 그룹핑해서 관리 하기 위한 자료구조 | 여러 데이터들을 순서대로 빈틈없이 적재하기 위한 자료구조(=시퀀스) |
| 인덱스가 변경되지 않는다(정해져있는 키값) | 인덱스는 몇 번째 데이터인지만 나타냄(순서번호) |
| 추가적인 삽입, 삭제가 일어나지 않으므로 검색에 유리 | 추가적인 삽이브 삭제가 일어남 |
| 데이터의 크기가 정해져 있음 | 데이터의 크기가 정해져 있지 않음 |
-> 파이썬에서는 list가 배열이다. 배열을 따로 제공하지 않음. 따라서 배열을 따로 사용하려면 numpy로 불러와야 한다.

# 앨리먼트(요소) 출력 : .index / .values
#Series 인덱스(index) 출력(=key)
a.index / a.keys() / a.keys
-> rangeIndex : 기본 인덱스 범위가 안정해졌을때 알아서 지정해준 그 인덱스의 범위를 표시해준다.

#Series 값(value) 출력 : values / a[인덱스번호]
-> array로 출력 / -1의 경우 거꾸로

#Series 자료형(type) 출력 : type()

# Series 인덱스(index) 생성 : pd.Series( 자료구조 데이터 ,index=['가','나','다'])
-> 딕셔너리일 경우, 키값이 시리즈의 인덱스로 설정되어 있기 때문에 시리즈를 생성할 때 새로운 인덱스를 부여하면 그 인덱스에 새로운 키로 생성 ->NaN

# 앨리먼트(요소) 변경
# 인덱스로 값(value) 변경
a['다']=100
# 인덱스(index) 변경
a.index = ['A','B','C']

DataFrame
# 자료구조 -> DataFrame 생성 : pd.DataFrame(자료구조)
자동으로 table 형태로 만들어진다.

# 앨리먼트(요소) 출력
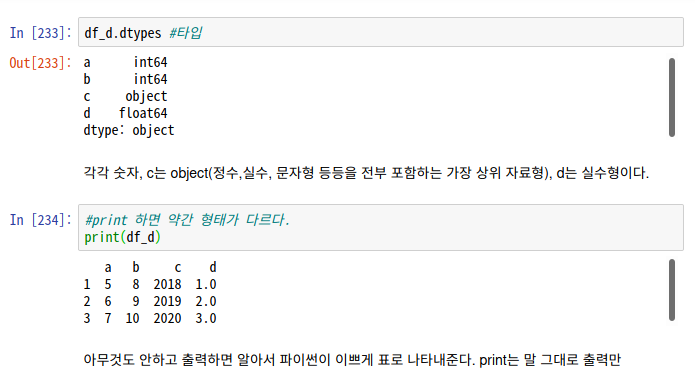
#타입 출력 : df.dtypes
#정보 출력 : df.info()
-> df.info는 모든 테이블 값들이 다 출력된다.
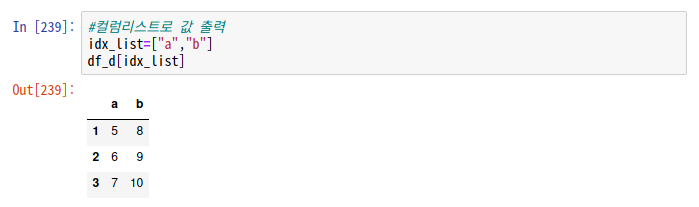
#컬럼별로 값 출력
print(df.컬럼명)
-> 컬럼명을 리스트로 묶어서도 가능 : df[idx_list]

# 컬럼과 인덱스 설정
df = pd.DataFrame(cc, index=[1,2,3], columns=[a,b,c])

# index와 column
- index(행) :가로로 한줄한줄 의미
- column(열):세로로 한줄한줄 의미
- 각각의 이름을 붙여준다면 index=[세로를 대표] column=[가로를 대표]
# index와 column 값 변경
#새로운 column 추가
-> 딕셔너리를 데이터프레임의 값으로 처리할 때 키값이 다를 경우, 또는 새로운 칼럼을 추가할 경우 그 값은 NaN 으로 처리된다.

# df.컬럼명 = 0.7 처럼 통일해서 채워넣거나, 데이터로 연산 가능.

# 컬럼명으로 값 변경 또는 추가

# 다양한 DataFrame 메소드
# 범위 안 정수 출력 (5부터 14까지) : arrage
# 배열/테이블 모양을 만들기 : reshape
-> reshape()는 다차원으로 변형이 가능

# Series 출력
키-값 쌍을 한 꺼번에 뽑아 내는 함수. generator 형식으로 뽑힌다. : items()
->generator : 리스트의 단점을 극복해서 리스트와 같은 자연현상을 조금 최소화 할 수 있다.

# 중복데이터 처리 (실제로는 사라지지 않음. 보여지기만 하는것.) : df.drop_duplicates()
-> df.drop_duplicates(inplace=True) : 바로 중복데이터 처리 적용(또는 초기화 : df = df.drop~~)

# 데이터프레임 크기 ex)5x3 형태 등 : df.shape
# 차원출력 ex) 2차원, 3차원 등 : df.ndim
#컬럼 삭제 : del
del df['컬럼명']
# 데이터 슬라이스
- df.loc[시작순서번호 : 끝순서번호] / [행범위,열범위] : 레이블 기반 인덱싱


- df.iloc[시작순서번호 : 끝순서번호] / [행범위,열범위] : 위치 정수 기반으로 인덱싱


# 비교연산자
-> 행(가로)을 가져온다.


# loc + 비교연산자


# and / or 연산자 + 비교연산자

[ 나눔고딕 폰트 설치 ]


base에 설치 후 주피터 노트북에 추가 설치 해야한다.
#폰트 확인(주피터에서 확인해야 가져올 수 있음)
!ls -l /usr/share/fonts/truetype/nanum | grep NanumGothic*
#캐시 삭제
!rm. -rf ~/.cashe/matplotlib/*
#가져온 폰트 설치
!fc-cache -fv#설치 되어있는지 보기 위해 matplotlib 폰트 매니저로 폰트 있는지 확인
import matplotlib
import matplotlib.font_manager
#나눔 이름 붙은 폰트 있니?
[f.name for f in matplotlib.font_manager.fontManager.ttflist if 'Nanum' in f.name]폰트를 설치한 후 한글이 깨지지 않는지 확인해준다.
#한글설정 #유니코드깨짐 #폰트설정
import matplotlib as mpl
import matplotlib.pyplot as plt
#유니코드 깨지는 현상 방지
mpl.rcParams['axes.unicode_minus'] = False
#폰트 설정
plt.rcParams['font.family'] = 'NanumGothic'
#테스트
plt.figure()
plt.grid(True)
plt.plot((1,1))
plt.title("한글테스트")
plt.show()
'[ Python ]' 카테고리의 다른 글
| [Python] Pandas 기초 / groupby / 데이터프레임 Json으로 저장 / 실습(3) (0) | 2020.10.30 |
|---|---|
| [Python] Pandas 기초 / DataFrame / matplotlib / 실습(2) (0) | 2020.10.29 |
| [python] 주피터 노트북(jupyter notebook) 단축키 (0) | 2020.10.28 |
| [Python] pandas 기초(3) - 문제풀이 (0) | 2020.10.28 |
| [Python] Pandas 기초/ DataFrame / Series / 실습 (0) | 2020.10.27 |