# 결측치
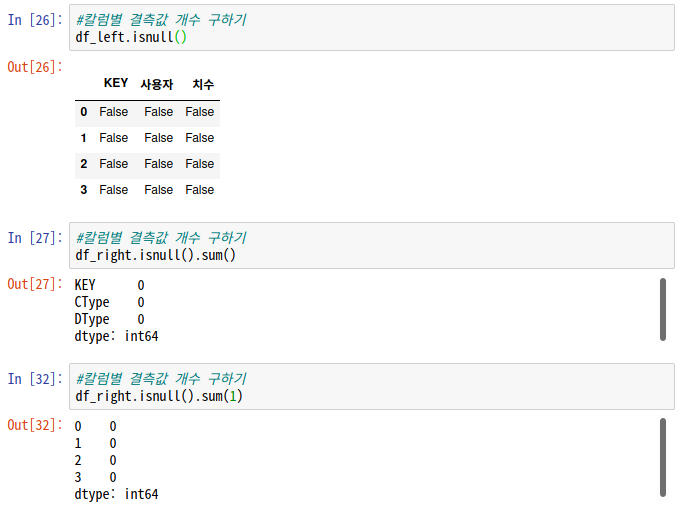
# 결측값이 있는지 여부 확인 : isnull()
# 결측값 없는 것들 확인 : notnull()
# 세로줄(열)별 결측값 갯수 : df.isnull().sum()
# 가로줄(행)별 결측값 갯수 : df.isnull().sum(1)
# 결측치 시각화하기 : missingno
▼missingno 설치 방법
!pip list |grep missingno
!pip list |grep missingno #설치 확인
#결측치를 시각화하는 방법 : missingno
import missingno as msno
msno.matrix(df_all,figsize=(18,6))
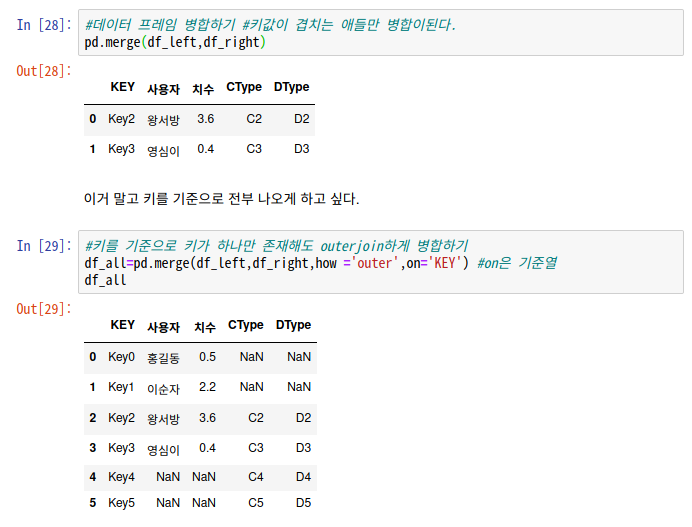
# 병합 : pd.merge()
- 그냥 merge를 쓰면 키값이 겹치는 애들만 병합이 된다.
-> 속성값으로 join의 종류(how)와 기준열(on)을 정할 수 있음.
df_all=pd.merge(df_left,df_right,how ='outer',on='KEY')
# 수치형 데이터 정보 출력(#산술통계)
# 데이터 요약정보 : describe()

- count : 갯수
=> 오라클에서는 count(sapay), count(*)
count(sapay) : null이 존재한다면 계산되지 않는 것 / count(*) : null이 있어도 계산됨
- mean : 평균
- std : 표준편차
- min : 최소값, 0
- max : 최댓값,100
- 4분위값 : 보통 머신러닝에서 이상치값 정리할 때 4분위를 나눠서 위아래를 잘라낸다.(박스플롯에서 사용)
->0사분위(최소값(min)), 1사분위(25%), 2사분위(50%, 중앙값(median)), 3사분위(75%), 4사분위(최댓값(max))
# 산술통계 연습하기
#numpy로 배열 생성
a= np.array([7,9,16,36,39,45,45,46,48,51])
#길이(갯수)
len(a) #10
#평균
np.mean(a)
#최대 #34.2
np.max(a)
#중위값
np.median(a) #42.0
#2사분위(50%)
np.percentile(a,50) #42.0
#1사분위(25%)
np.percentile(a,25) #21.0
#표준편차
np.std(a) #16.054905792311583
#describe 할 때는 데이터 프레임으로 바꿔서 써야한다.
mydata = pd.DataFrame(a)
mydata.describe()+추가
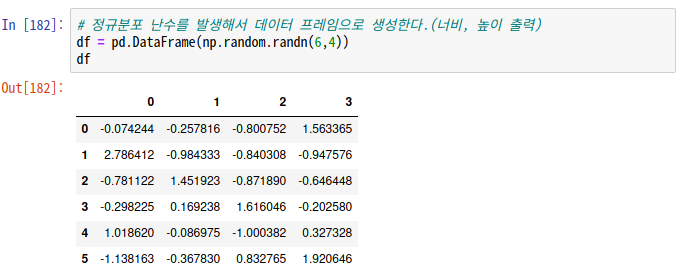
#정규분포 생성하기 : np.random.randn()
- 랜덤한 정규분포 난수를 발생해서 DateFrame을 생성한다. 괄호 안(너비,높이) 크기만큼의 정규분포행렬이 생성된다.
#유일한 값별로 갯수 세기 : value_counts()
# 백분위수 구하기 : percentile()
(numpy 함수) np.percentile(데이터, 백분위수, 파라미터 옵션)
- 백분위수(Percentile)는 오름차순 정렬했을 때 0을 최소값, 100을 최대값으로 백분율로 나타낸 특정 위치 값
- 사분위수는 25, 50, 75를 기준 점으로 나눠져 1분위부터 4분위까지 존재하게 된다. 백분위수 q 값은 0부터 100 값을 사용한다.

[interpolation 파라미터 옵션]
정렬된 데이터 i와 j가 있을 때,
- linear : i + (j - i) * fraction (기본값)
- lower : i
- higher : j
- nearest : i or j whichever is nearest
- midpoint : (i + j) / 2각 결과 비교

# NaN 데이터 처리(# null값 처리)
왜 필요해?
보통 머신러닝에서 연속형일 경우에는 0에 대한 데이터가 많아지면 문제가 생기기 때문에 null 값 또는 0에 대해 따로 전처리를 한다.
# NaN 값을 다른것으로 대체 : fillna()
a['컬럼명']=a['컬럼명'].fillna(바꿀값) -> 초기화시켜주는 것.

# NaN값 추가 : np.NaN
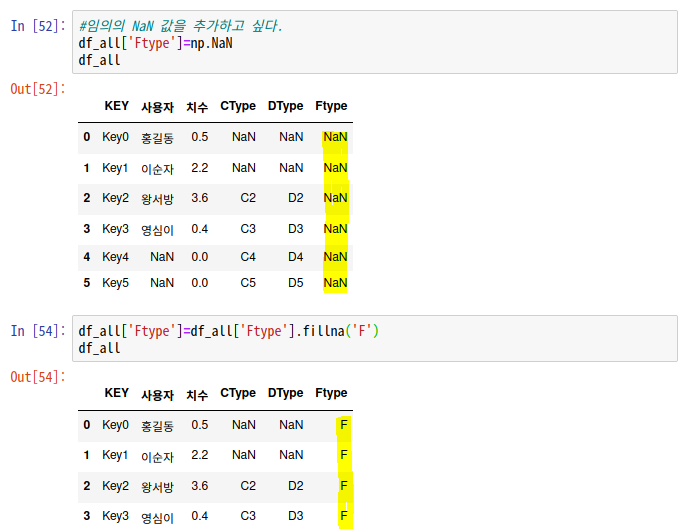
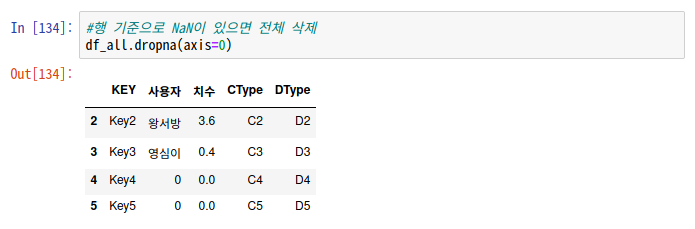
# NaN값이 있으면 전체 삭제 : dropna()
#행 기준 : dropna(axis=0) / 열 기준 : dropna(axis=1)

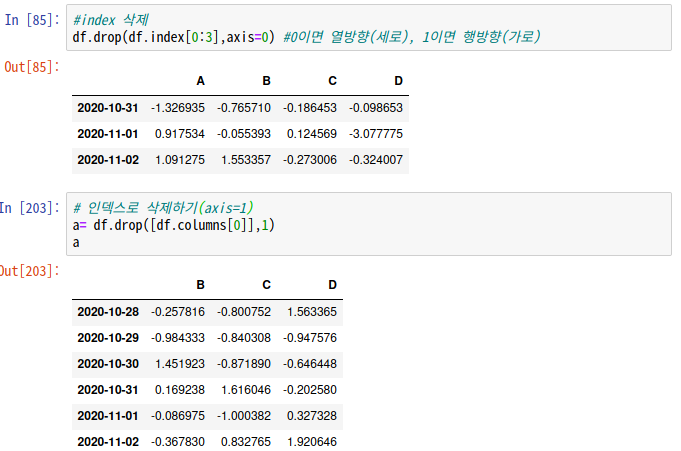
# 데이터 삭제 : drop()
# index 삭제(가로줄 전체 삭제) #column 삭제(세로줄 전체 삭제)
df.drop(df.index[0:3],axis=0)
: 인덱스순서번호로 0번부터 3번까지 행방향(가로줄)로 삭제
0이면 열방향(세로), 1이면 행방향(가로)axis=0 / 그냥 숫자만 적는 것도 가능
# 인덱스번호로 삭제
df.drop([df.columns[0]],1)
: 인덱스순서번호로 0번 열방향(세로줄)로 삭제(그냥 숫자만 적음)
# 데이터 앞, 뒤, 중간 뜯어보기
#데이터 상단만 보기 : head()
#데이터 하단만 보기 : tail() #데이터 끝
#데이터 중간만 보기 : loc 사용

++추가
# 일부 데이터 값 변경하기
- loc[범위] ->콜론 : [시작순서번호 : 끝순서번호] / 콤마 : [행범위,열범위]


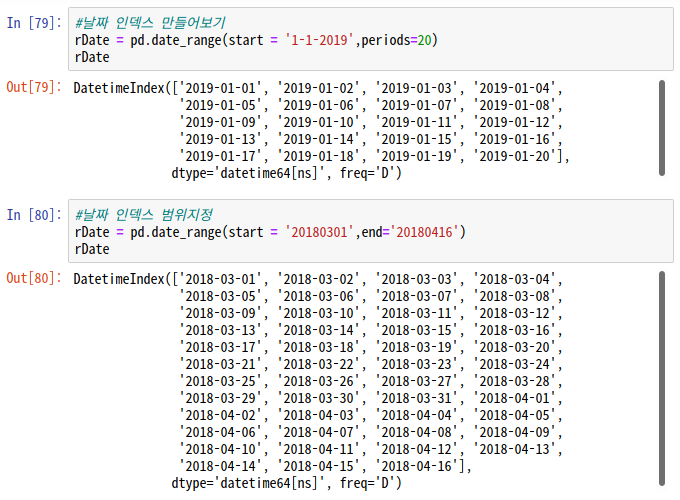
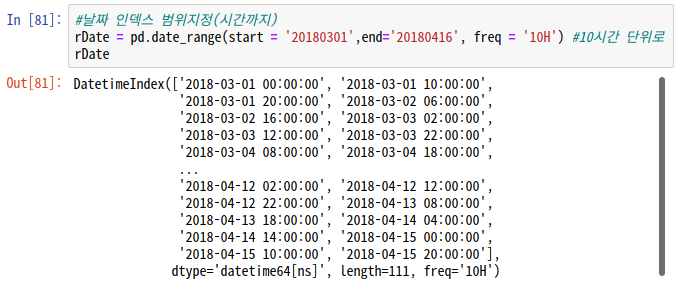
#날짜 인덱스 지정하기 : date_range
pd.date_range(start = '날짜',end='날짜', freq = '시간단위')
-> 시작점만 지정해준 뒤 periods로 범위를 지정해줄 수도 있다.
# bar 차트 그리기 #막대그래프
# Matplotlib이란?
파이썬에서 데이타를 차트나 플롯(Plot)으로 그려주는 라이브러리로 가장 많이 사용되는 데이타 시각화(Data Visualization) 패키지. 라인 플롯, 바 차트, 파이차트, 히스토그램, Box Plot, Scatter Plot 등을 비롯하여 다양한 차트와 플롯 스타일을 지원한다.
- 수입
import matplotlib as mpl
import matplotlib.pyplot as plt
#또는
%matplotlib inline
"%matplotlib inline" 를 넣게 되면, Shift + Enter를 치지 않고 Run 버튼을 눌러 실행하여 그래프를 얻을 수 있다.
이러한 % 명령은 Cell Magic 명령어라고 불리우는 것으로 이는 파이썬 코드가 아니라 Jupyter에게 특정 기능을 수행하도록 하는 명령이다. %matplotlib inline 명령은 Jupyter에게 matplotlib 그래프를 출력 영역에 표시할 것을 지시하는 명령이다.(출처)
- 차트 그리기
plt.plot(["Seoul","Paris","Seattle"], [30,25,55]) #차트 내용
plt.show() #차트출력
#또는
데이터이름.plot(kind='bar')차트의 모양과 출력만 있으면 된다. 나머지는 옵션.
- 차트 옵션
다양한 옵션이 있다.
plt.bar(aa['student'],aa['kor'],color='#ffcc00',width=0.3,align='edge',label='kor')-> plt.bar() 자체로 차트를 그릴 수 있다.
차례대로 x축데이터, y축데이터, 차트색깔, 폭, 차트위치,라벨이름 이다.
이 차트의 경우 가로로 되어있어서 height가 아닌 폭(width)로 두었다. 라벨 이름은 기본값으로 center로 설정되어있고, align='edge' 왼쪽 모서리를 의미한다.
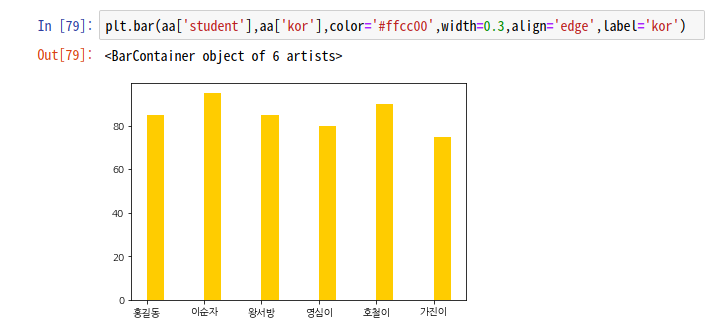
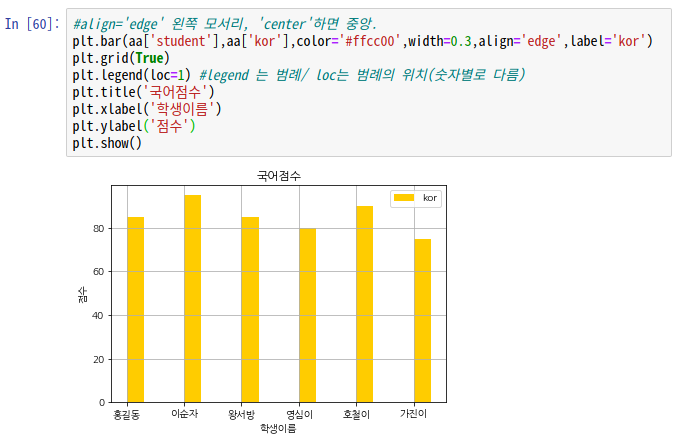
plt.bar(aa['student'],aa['kor'],color='#ffcc00',width=0.3,align='edge',label='kor')
plt.grid(True) #격자무늬
plt.legend(loc=1) #legend 는 범례/ loc는 범례의 위치(숫자별로 다름)
plt.title('국어점수') #제목
plt.xlabel('학생이름') #x라벨
plt.ylabel('점수') #y라벨
plt.show()
이런식으로 옵션을 추가할 수 있다.
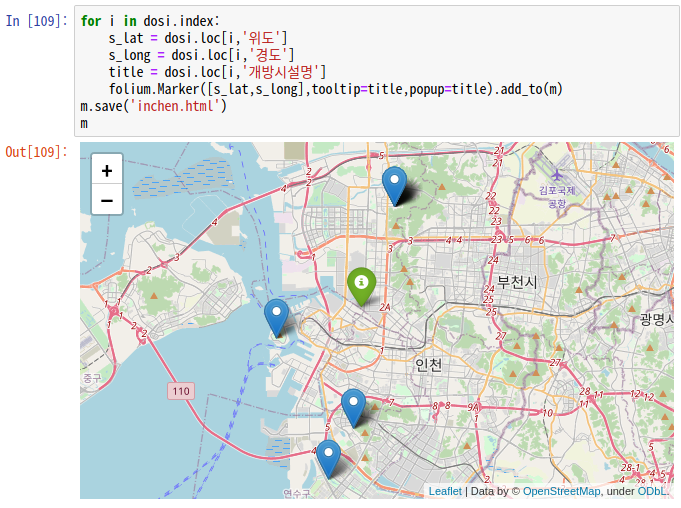
#지도데이터 시각화 : folium #위도 경도로 지도 그리기
eaflet.js 기반으로 지도를 그려주고, 모바일에서도 쓸 수 있을만큼 가벼운 시각화 패키지.
지도 표시 : folium.Map(location=[위도,경도],zoom_start=줌범위)
!pip install folium #설치
import folium #수입
#위도와 경도를 찍어서 지도 표시하기
m = folium.Map(location =[35.873626,128.545482],zoom_start=15) #zoom_start = 10 :기본값
m.save('data1.html') #html로 저장
m
Marker 추가 : folium.Marker([위도,경도],tooltip='툴팁이름'popup='팝업이름').add_to(m)
'[ Python ]' 카테고리의 다른 글
| [Python] SciPy / 기초기술통계 / 카이제곱검정 / T검정 (0) | 2020.10.30 |
|---|---|
| [Python] Pandas 기초 / groupby / 데이터프레임 Json으로 저장 / 실습(3) (0) | 2020.10.30 |
| [python] 주피터 노트북(jupyter notebook) 단축키 (0) | 2020.10.28 |
| [Python] Pandas 기초/ Series /DataFrame / 실습(1) (0) | 2020.10.28 |
| [Python] pandas 기초(3) - 문제풀이 (0) | 2020.10.28 |