메인메소드 뜻
[JAVA] 메인메소드 public static void main(String[] args) 를 이해하자
public static void main(String[] args) java 를 한번이라도 배워보신분들은 다들 알고계신 메인 메소드 에대해서 얘기해보도록 하겠습니다. 정말 기본적인 내용이니 어느정도 알고계신분들한테는 뻔한 내
javacpro.tistory.com
abstract의 의미. 추상클래스와 추상메소드
[Java-자바]추상 클래스 및 추상 메서드(abstract class and abstract method)
추상메서드란 "추상" 사전적 의미로 "여러가지 사물이나 개념에 공통되는 특성이나 속성따위를 추출하여 파악하는 작용"이라는 의미이다. 추상화 : 클래스간의 공통점을 찾아내서 공통의 부모
sungwoon.tistory.com
final과 상수 / 오버라이딩 불가.
왜 자바에서 final 멤버 변수는 관례적으로 static을 붙일까?
자바 final, static 키워드와 코딩 best practice 되짚어보기
djkeh.github.io
자바 클래스 지정자 정리
<클래스 정리>
* 접근지정자 : public / private / default / protected
* 추상클래스/메소드 -> 덜 완성된 틀만 형성해서 자식이 제대로 안을 채워서 쓸 수 있게 함.
* abstract class : 클래스에 바디가 없는 메소드가 1개 이상. 따라서 "객체 생성이 불가" -> 기능없이 비어있다.
* abstract 메소드 : 리턴,메소드명,매개변수만 정의되고 실행될 구문이 없음(바디없음). -> 안에 채워서 써라.
* final class : 이 클래스는 상속이 되지 않는다(자식이 없다).
* final 메소드 : 오버라이딩(재정의) 불가. 클래스 상속이 되도 자식클래스에서 이 메소드는 값(실행구문)을 바꿀 수 없다.
* static 변수 = 데이터; : 자료형 선언 없이 가져다 쓸 수 있다. (java04_Constructor2 참고)
* static 메소드 : 객체 생성 없이 이 메소드 가져다 쓸 수 있다.
* final 변수 : 갱신금지. 이 변수 데이터는 덮어써지지 않는다.
* 생성자는 생성자명(매개변수){실행구문;}으로 되어있고, this.변수 로 그 생성자값 가져올 수 있다.
* void 메소드 : 리턴이 없는 메소드. 행동만 하고 끝. return;은 가능하지만 return a;는 불가능.
* return은 "자료형 메소드" 형태로 return에서 그 자료형 타입을 리턴해줘야한다.
JVM 구조
JVM : 자바가상머신. 자바 바이트코드를 실행시키는 주체. 운영체제 종류와 무관하게 가능
* 즉, 운영체제 위에서 동작하는 프로세스로 자바를 컴파일해서 얻은 바이트코드를 기계어로 바꿔서 실행시키는 역할.
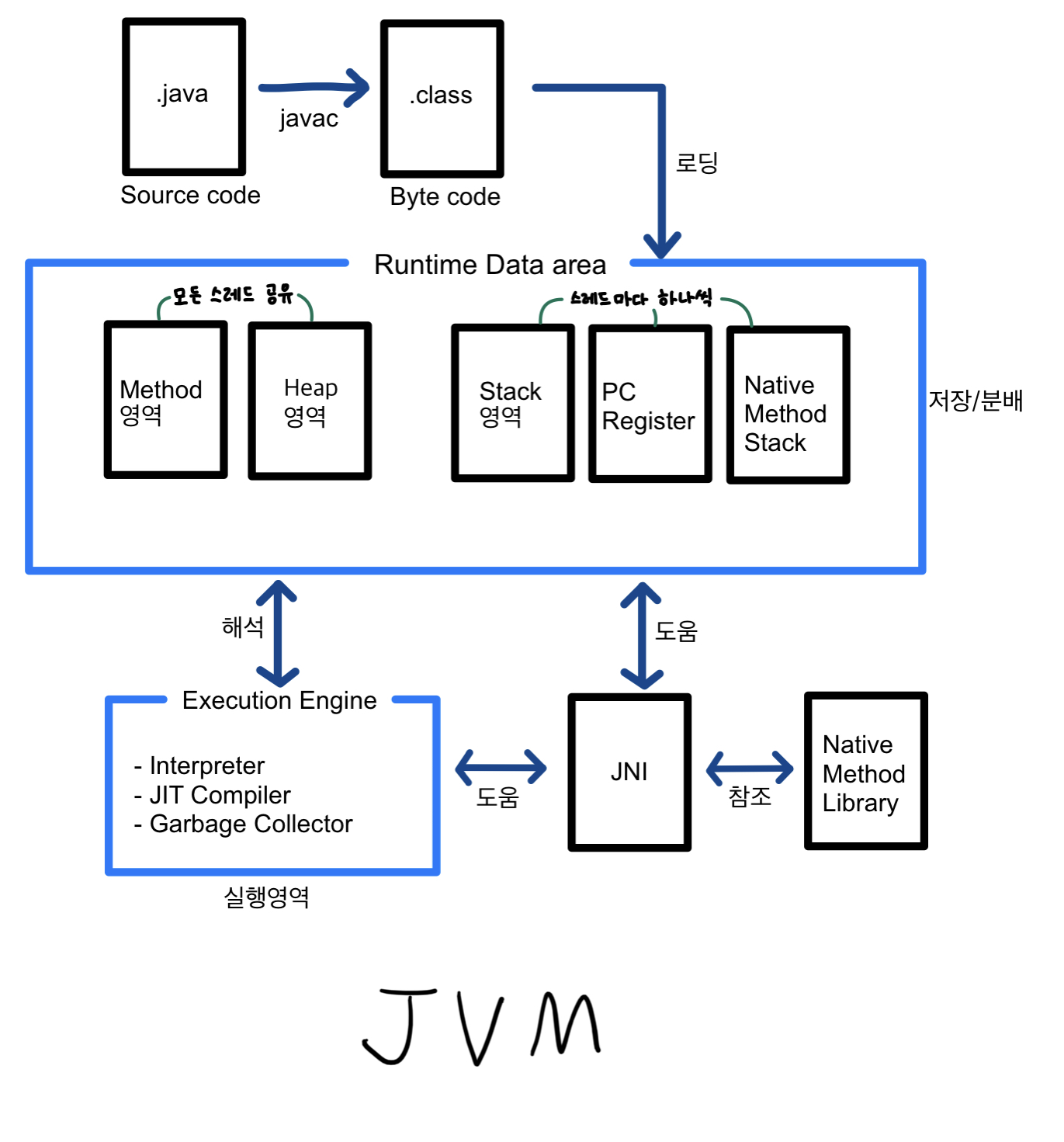
* 1. 소스코드 -> 바이트코드
* 소스코드는 .java로 저장한다.이걸 자바 컴파일러(javac)가 바이트코드로 바꿔주는데 그건 .class로 저장한다.
* 왜? 일단 1차적으로는 코드 숨기기, byte코드로 바꾸면 문법검사같은건 안하게 되면서 실행 시간이 단축됨.
* 근데 이러면 소스코드 변경할때마다 또 컴파일러가 .class로 byte코드로 변경하니까 번거로움.
*
* 2. 바이트코드 -> Runtime Data Area
* 이렇게 변경된 byte코드(.class)파일들은 class Loader가 Runtime Data Area로 로딩시킨다.
* Runtime Data Area는 5가지 영역으로 되어있는데,
* 1. 메소드영역 , 힙 영역 : 모든 스레드가 공유하는 영역
* 2. stack, PC Register, Native Method Stack : 스레드마다 하나씩 생성되는 공간
* 이렇게 나뉜다.
*
* 하나씩 보자.
*
* 1) method 영역
* JVM이 시각될 때 생성되는 공간으로 byte코드(.class)가 여기에 저장된다.
* 그리고 모든 스레드가 공유하는 영역이니까 클래스의 정보, 변수 정보, static으로 선언한 공유변수가 저장되고 모든 스레드가 공유한다.
*
* 2) heap 영역
* 동적으로 생성된 객체가 저장되는 영역, 즉 new 연산으로 동적으로 생성된 인스턴스(클래스가 객체가 된 것)가 여기에 저장된다.
* 클래스의 객체, 배열 등 쉽게 소멸되지 않는 데이터가 있다.
*
* heap 영역은 가비지 콜렉터(GC)의 영역이 된다. heap도 크게 3가지로 나뉘는데, young/old/permanent 이다.
*
* 2-1)GC(가비지 콜렉터)
* 가비지 콜렉터란 정리되지 않는 메모리, 유효하지 않는 메모리 주소로,
* 예를 들어 첫 초기화 이후에 값을 또 할당했을 때 값이 덮어씌워지는데, 그 전에 선언했던 값이라던지
* 선언은 해서 메모리는 가지고 있는데 사용이 되지 않은 값이라던지를 자바에서는 garbage라 부른다.
* 메모리가 부족할 때 가비지를 메모리에서 해제시키고 공간만들어주는 것이 GC의 역할.
* 크게 Mark와 Sweep 과정으로 나뉘는데,
* Mark는 변수나 객체를 스캔하면서 어떤 객체 참조하는지 찾는 과정(=도달성(reacheable))이고(이때 스탑함),
* Sweep는 Mark가 안된 객체를 힙에서 제거하는 과정이다.
* GC가 Mark and Sweep를 거치며 가비지를 구분할 때 도달성(reachable)이라는 개념이 있는데,
* 객체에 유효한 레퍼런스가 있는지(=객체를 참조하는지)를 말한다.
*
* 2-2)Stop The World
* GC가 실행되려면 JVM이 애플리케이션 실행을 잠시 멈춰야한다. 그걸 Stop The World라고 한다.
* 멈추는 시간을 줄이는 것을 GC 튜닝이라고 한다.
*
* 2-3)heap 영역의 구조
* Young 영역에서 발생한 GC를 Minor GC, old/permanent 영역에서 발생한 GC를 Major GC(Full GC)라고 한다.
*
* 쉽게 말해 young은 새롭게 생성된 객체가 위치해서 대부분 생성되었다가 사라지는 곳.
* old는 reachable 상태가 유지되서 살아남은 객체들 모음. GC가 적게 발생함.
* perm은 메소드랑 비슷하다. 클래스와 메소드 정보가 들어있는 곳.
*
*
* 3) Stack 영역
* 스택은 지역변수나 메서드의 매개변수, 임시 사용된 변수, 메서드의 정보가 저장되는 영역.
* 지역변수나 매개변수는 메소드가 호출이 종료되면 그 안에 있는 변수는 사라진다.
* 즉, 금방선언되고 금방 사라지는 애들이 여기 있다가 없어진다.
*
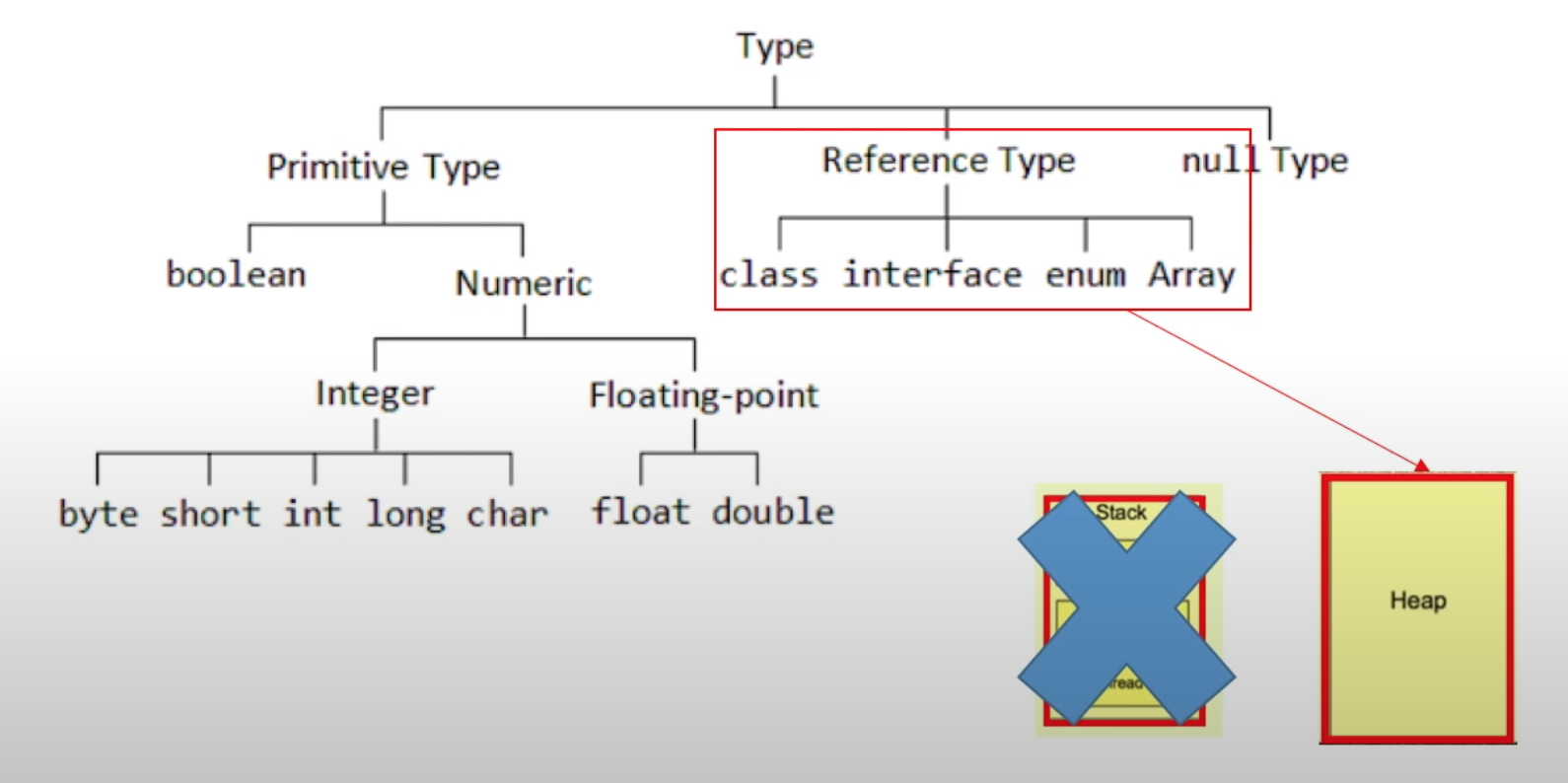
* 즉, class a(변수명) = new 생성자명(생성자 안에 들어갈 데이터);
* 여기서 a는 스택에 저장된다. 생성자명(데이터)는 heap 영역에 저장된다.
* 왜? 원래 자바의 레퍼런스 타입(클래스,인터페이스,배열,상수)들은 구조가 복잡하고 용량이 크다.
* 이것들까지 스택에 보관해서 그때그때 뽑아쓰면 비효율적이므로 heap에다가 저장 후,
* 얘네들 주소를 참조하는 변수(a)를 스택에다가 저장해서 불러오는 것이다.
* 4) PC Register 영역
* 스레드가 어떤부분을 어떤 명령어로 수행할지 저장하는 공간.
* 스레드가 시작될 때 생성되며, 현재 수행되는 JVM 명령어 주소를 저장한다.
*
* 5) Native Method Stack 영역
* 자바를 제외하고 다른 언어,C언어나 C++언어가 실행되는 공간.
* 자바 프로그램이 컴파일 된 byte코드(.class)가 아니라 실제로 실행 가능한 기계어(0101)를 실행시키는 영역.
*
*
*
* 3. Runtime Data Area -> Execution Engine 영역 : 해석할 차례
* 로드된 클래스 파일의 byte코드를 실행하는 곳. 여기서 컴퓨터가 이해할 수 있는 기계어로 바꾼다.
* 방법은 두가지.
* 1. 인터프리터 : 명령어 한줄한줄 해석하면서 실행. 2. JIT(just-in-time) 컴파일러 : 한줄한줄말고 런타임에 전부 한번에 실행.
*
* 여기서 해석한 것을 다시 Runtime Data Area로 가져가서 배치하고 스레드가 동기화되거나 가비지 컬렉션에 들어간다.
*
*
* 4. JNI(Java Native Interface) 영역
* 추가로 JNI는 JDK의 일부분인데, 다른 언어로 쓰여져있는 애플리케이션이나 라이브러리가 자바 가상머신과 상호작용을 할 수 있게 도와준다.
JVM 구조와 자바 런타임 메모리 구조 (자바 애플리케이션이 실행될 때 JVM에서 일어나는 일, 과정
JVM(Java Virtual Machine) : 자바 가상 머신으로 자바 바이트 코드를 실행할 수 있는 주체다. CPU나 운영체제(플랫폼)의 종류와 무관하게 실행이 가능하다. 즉, 운영체제 위에서 동작하는 프로세스로 자
jeong-pro.tistory.com
GC(가비지 콜렉터)
가비지 컬렉터(GC)에 대하여
얼마 전 N사 전화면접에서 GC에 대한 질문을 받고 그대로 얼어버린 경험이 있다. GC에대해 들어본 적은 있으나 동작원리나 관련 내용들을 제대로 몰라 할 수 있는 말이 없었다. 그래서 이번 포스
velog.io

자바 JNI
자바 JNI 개인정리
[JNI] - Java Native Interface의 약자로, 자바로, C와 C++의 코드를 실행시키는 인터페이스를 말합니다.(꼭 C C++에 국한된 것은 아니지만, 실질적으로 사용되는 것이 C/ C++입니다.) (기본 설명) - SW 프로그
wiserloner.tistory.com
웹서버 프로그램 구조 정리
/* <웹 서버 프로그램 구조>
* 1. 클라이언트한테 요청을 받으면 서버가 DB에서 웹문서를 찾아본다. 있으면 그냥 바로 전달(정적인페이지 ex)로그인페이지 이동)
* 2. 원하는게 없다. 그러면 그걸 찾을 수 있는 서블릿 컨테이너 속 코드(서버 앱)를 찾는다.
* 3. WAS가 자바 언어로 된 서블릿을 실행해서 동적인 페이지를 만든다.
* 4. 다시 클라이언트한테 응답한다.
* 웹을 통해 통신하는 양 끝에는 클라이언트와 서버가 있다. 클라이언트는 요청자, 서버는 제공자(DB)이다.
* 클라이언트와 서버가 동기화가 되어야 두개가 동시에 변하는데, 서버는 하나라서 한번만 변하면 되지만 클라이언트는 여러명이므로 각각 업데이트 해야 한다.
* 예전에는 소프트웨어 업데이트가 자동 업데이트가 아니라 재설치의 개념이라 다른 프로그램 영향도 받고 해서 서버가 배포도 힘들고 클라이언트가 각각 업데이트도 힘들었었다.
* 그래서 웹이라는 것을 사용하게 된 것!
*
* 일단 IP 주소는 네트워크 주소로, 웹에서 찾아가기 위한 주소이다.
* 그리고 그 네트워크 주소를 받아서 네트워크에 연결해서 인터넷을 이용하기 위해 연결된 컴퓨터 또는 장치를 호스트라고 한다.
* 그리고 네트워크 공간에 있는 모든 장치를 노드라고 한다. 즉, 호스트는 네트워크 이용을 위해 네트워크 주소가 할당된 노드이다.
* 서버는 요청에 응답할 수 있는 호스트이다. 클라이언트는 네트워크상에서 요청을 하는 호스트이다.
* 결국 네트워크상에서 대부분 요청과 응답의 형태로 데이터가 오가는데 그 주체들이 호스트인 것.
*
* 실제로 데이터를 주고받는 것은 호스트 내에 있는 프로세스들인데, 이 프로세스는 프로그램,애플리케이션,소프트웨어 등등이 있다.
* 데이터는 호스트 안에 있는 프로세스들이 주고받기 때문에 호스트에 도착하고 나서도 프로세스를 찾아야한다.
* 따라서 호스트 내부의 프로세스 주소도 필요하다. 그게 포트(port)이다. 우편번호라고 생각하면 될듯.
*
* 소캣(socket)은 프로세스가 네트워크를 통해 데이터를 전달할 때 반드시 열어야하는 창구이다. (데이터 보내는 빨대같은 것)
* 즉, 이쪽에서도 저쪽에서도 소캣을 열어야 정보를 보내고 받는 것. 소캣은 프로토콜(규약),IP주소,포트넘버로 정의된다.
* 프로토콜 종류에 HTTP(인터넷에서 데이터 주고받을 수 있는 프로토콜,상태가 없어서 데이터 요청과 응답이 독립적으로 관리됨),TCP/IP(인터넷 통신망에서 정보 주고받는 기능을 이용한 프로토콜)이 있다.
*
* HTTP는 웹이다. 웹에서는 이미 브라우저가 있어서 그걸 요청할 수 있는 환경을 갖춰져있고, 그 요청에 대해 웹서버가 요청을 응답해준다.
* 예를들어 만약 브라우저가 www.naver.com 주소를 에서 /login을 붙이면(요청) 웹서버가 페이지를 찾아서 로그인페이지를 응답해준다.
*
* 즉, 이 구조를 이용해서 우리가 문서에 글씨로 써서 컴퓨터에게 요청하면 컴퓨터 서버가 그걸 변환해서 엑셀로 돌려주는 것을 웹페이지 구조에 "얹어서" 사용하자는 것.
*
* 왜 "얹어서" 사용하냐면, 웹페이지는 이미 정적으로 정해진 것들만 전달한다.(로그인페이지,웹툰페이지 등 주소 치면 딱 한장으로 나오는 정적 페이지)
* 하지만 우리는 업무를 위해서 사용한다. 예를들어 회원 목록, 정보리스트 등을 추출해서 응답받기를 원하는데, 그러려면 서버 단에서 그걸 변환해서 보내줘야한다.
* 즉, 클라이언트가 문서를 요청하면 서버단에서 동적으로 문서를 만들어서 사용자 목록을 만들어 응답해준다. 그걸 받기 위해 따로 클라이언트 프로그램을 만들 필요는 없다.
* 왜냐면 문서로 전달되니까, 그걸 브라우저로 받으면 되는거고, 대부분 윈도우에는 브라우저가 다 있다.
* 그러므로 우리가 만드는 것은 웹개발을 이용한 (요청의 답으로 동적인 문서를 만들어서 응답하는) 서버 프로그램인 것!
*
* 예전에는 웹개발자다 하면 서버프로그램을 만드는 개발자였는데 요즘은 클라이언트 단에서도 자바스크립트로 웹기반 클라이언트 프로그램을 만드는 사람도 생겼다.
* 그래서 웹서버, 백엔드 개발자 그리고 클라이언트, 프론트앤드 개발자가 생기게 된 것이다.
* 정적인 데이터가 아니라 동적인 데이터를 전달할 때, 우리는 한가지 기능이 더 필요하다.
* 예를들어 회원 리스트를 달라고 했다고 하자. com/member/list로 클라이언트 어플리케이션이 요청을 보냈다.
* 과거방식이면 웹서버는 홈 디렉토리에서 있는지 찾아보고 찾아서 꺼내보면 웹문서 형태일 것이다. 그리고 그걸 그대로 전송해주었다.
* 근데 회원 목록이 문서로 미리 만들어져있는건 대체로 불가능하다. 데이터는 업데이트 되기 때문에 웹문서로 만들어져있다고 해도 원하는 정보가 아닐 가능성이 높다.
* 홈 디렉토리에 있는 것이 코드라고 해보자. 어떤 언어로 만들어져있던지 간에 그 코드가 있으면 DB에서 그 코드를 실행해서 찾을 수 있다.
* 이 코드를 Server app이라고 부른다.
* 즉, 그 코드를 클라이언트 어플리케이션에 돌려주는 것이 아니라,
* 그 코드를 실행하고, DB에서 찾아서, 받은것을 웹문서화해서 돌려받는 기능을 하는 무언가가 필요하다.
* 얘를 웹 어플리케이션 서버, WAS라고 한다. WAS에는 대표적으로 Tomcat이 있다.
*
* 즉, 우리는 서버단에서 클라이언트의 요청에 응답하기 위해
* 1. 동적인 문서를 만드는 Sever app에게 요청하는 Web Server환경
* 2. 서버 앱이 만든 문서를 실행하는 환경인 WAS(웹 어플리케이션 서버)환경이 필요하다.
*
* 그렇다면 서블릿은 무엇일까?
* 서블릿은 서버에서 동적인 웹페이지를 만들기 위해 DB에서 원하는 정보를 가져올 수 있는 서버 앱이 자바로 쓰여져 있는 "웹서버 응용 프로그램"이다.
* 예를 들어 회원목록을 달라고 했을 때, 서버 앱에서는 list라는 이름의 자바 코드를 실행한다.
* 이 코드를 서블릿이라고 했을 때, 서블릿은 최초로 요청시에 객체가 생성되고, 재사용 되기도 하며, 서버가 중지되면 삭제된다.
* 서블릿 : 자바로 쓰여진 동적인 움직임을 만드는 웹 서버 응용 프로그램. 이것들이 뭉쳐진 저장소를 서블릿 컨테이너라고 부른다.
*
* Apache는 정적인 데이터를 처리하는 웹서버이고, Tomcat은 WAS중에 하나로 동적인 처리를 하는 서블릿 컨테이너이다.
* 자바 개발시 필요한 도구들을 JDK(Java Development Kit)라고 한다.
* 자바 가상머신(JVM)의 실행환경을 구현한 도구를 JRE(Java Runtime Environment)라고 한다. 라이브러리나 환경파일들이 있다.
*
* 그래서 우리가 자바 프로그래밍을 할 때 JDK를 JAVA_HOME라는 약속한 이름의 경로에 두는거고, JRE를 라이브러리에 추가하는 것이다.
* 톰캣도 WAS 종류이기 때문에 런타임 서버로 추가 등록한다.
* 또 포트번호가 겹칠수도 있다. 그러면 데이터를 전달하는 주소지(우편번호)가 겹쳐지기 때문에 안될 수 있으니 포트번호 잘 기억해둬야 한다.
소켓(Socket) 포트(Port) 뜻과 차이
나도 개발자지만 소켓과 포트의 정확한 의미 차이가 헷갈릴 때가 있어서, 최근에 다시 꼼꼼하게 공부를 했...
blog.naver.com
톰캣 실행 시, 앞에 프로젝트 이름이 있는게 싫을 때, root 프로젝트 설정하는 법.


서블릿과 JSP
/* 원래 IDE(통합 개발환경)을 쓰면 OS 상관없이 이렇게 안해도 쉽게 할 수 있다. 하지만 개별로 쪼개보자.
*
* <서블릿 프로그램>
* 서블릿은 조각이기 때문에, 요청된 조각만 로드된다. 즉, list를 달라면 리스트에 해당하는 코드만 WAS에 의해 실행되고, 나머지는 실행되지 않는다.
* 서블릿 코드는 WAS에 의해 로드되고 실행되기 떄문에 클래스명은 상관이 없다. 중요한 것은 서블릿인지의 표시.
* 예를들어 약속되어있는 인터페이스명이거나, 추상클래스이거나. 추상클래스 형태로 서블릿을 참조한다.
* 서블릿을 참조한 추상클래스라면, 그 안에 있는 서비스(Service)라는 약속된 이름의 메인함수(메인이 붙지 않음. service라고 붙음)를 참조하게 된다.
*
* 예제)서블릿을 참조하는 추상클래스를 만들어서 안에 service라는 이름의 메소드를 가진 자바 코드를 만든다. 이걸 메모장에 붙여넣고
* 콘솔창에서 javac 이름.java 해서 실행하면 오류가 난다.왜?서블릿 라이브러리는 JDK에 포함이 안되어있기 때문에.
* 톰캣 폴더의 lib에 보면 servlet api 파일이 있다. 이걸 옵션으로 두고 자바를 실행하면 오류없이 실행된다. 그럼 그 폴더에 .class 파일이 생긴다!
* -> javac -cp(라이브러리 읽을께) 서블릿 api 이름 java
* 자, 생성된 .class 파일은 보통 WEB_INF 안에 classes 폴더 안에 들어간다. 그럼 클라이언트가 주소를 줄 때 그 클래스를 콕 찝어서 요청하면 안되나?
* ㅇㅇ 안된다. 왜냐면 WEB_INF는 클라이언트가 들여다볼 수도 없고 요청할 수도 없는 공간이기 때문. 즉, 비공개 공간이다.
* 홈 디렉토리 안에 있는 /nana.txt는 불러도 잘 실행된다. 하지만 WEB_INF는 안되는 것.
* 그럼 이걸 사용자가 요청하려면 어떻게 해야하나?
* 우리는 클라이언트가 요청하는 URL에 해당하는 서블릿 코드를 실행후 주기 위해 "매핑" 작업이 필요하다. 4를 달라고 하면 4로 매핑된 서블릿을 준다.
* 이걸 어디서 설정하냐? web.xml에서 설정한다.
*
* 서블릿 이름이 Nana.java이고 실행되어 classes 폴더 안에 Nana.class로 저장되어있을 때,
* com/4 로 요청하면 그에 매핑된 클래스인 Nana class를 돌려준다.
<servlet>
<servlet-name>kosmo</servlet-name>
<servlet-class>Nana</servlet-class> <!--패키지가 있으면 패키지명도 다 써줘야함.-->
</servlet>
<servlet-mapping>
<servlet-name>kosmo</servlet-name>
<url-pattern>/4 </url-pattern>
</servlet-mapping> * -> 가명을 설정해서 알아보는 느낌이라 생각하자. url 뒤에 붙은게 뭔지.
* 서버가 홈 디렉토리에 찾아봐도 같은 이름의 코드가 없으니 WAS로 넘겨서 매핑된게 있는지 찾아보고, 있으면 실행하는 것.(보안)
* sysout 해도 서버의 콘솔에 실행된다. 그럼 클라이언트에게 다시 응답해주려면 어떻게 해야하나? -> 그게 response다.
*/
import javax.servlet.*;
import javax.servlet.http.*;
import java.io.*;
//서블릿을 참조하는 추상클래스
public class c_servlet extends HttpServlet{
//http의 요청을 받는 도구 //응답을 주는 도구
public void service(HttpServletRequest request, HttpServletResponse response)
//예외
throws IOException, ServletException{
//원래 입출력은 Stream을 쓴다. 스트림의 기능들을 써보자.
// 1. os라는 변수에 담을껀데, 우리 응답할꺼야.
OutputStream os = response.getOutputStream();
// 2. 대충 우리 응답하는데에 출력할꺼야.
PrintStream out = new PrintStream(os, true);
// 3. 이 문장을 출력해줘.
out.println("Hello,Servlet!!");
}
}/* 이러면 클라이언트 웹페이지에 Hello, Servlet
*
* 자바는 스트림이 있고 Writer 계열이 있다. 다국어(=한국어)면 Writer.
* 위에서는 Hello,Servlet이 영어라서 스트림 쓴것.
프로젝트 마이바티스....
[MyBatis] resultMap 과 resultType (resultClass) 의 차이점
옆자리 친구가 뭔가 이상하다고 해서 모니터를 들여다봤더니 로컬 서버에 띄운 프로그램을 통해 실행한 쿼리의 결과는 0행인데 똑같은 쿼리를 DBMS 툴에서 실행하면 2행이 나오고 있었다. 대체
dorongdogfoot.tistory.com

'[ 개발 지식 ]' 카테고리의 다른 글
| 일반인에게 설명하는 [자바 프로그램의 실행 과정] - 2. 자바 프로그램 실행 (0) | 2022.09.19 |
|---|---|
| 일반인에게 설명하는 [자바 프로그램의 실행 과정] - 1. 프로그램 실행 (2) | 2022.09.19 |
| 컴퓨터 구조와 메모리(스택, 힙, 메모리 계층 구조) (2) | 2022.09.19 |
| [JS] 협업 툴 개념 및 정리 - node.js 패키지 툴(npm, yarm, brew) / Git 클라이언트 프로그램(Fork, Gitlab, gitbash) (0) | 2021.03.08 |
| 개발자 면접 준비 중 헷갈릴만한 단어 정리 (0) | 2020.11.16 |