
아아주 기초적인 지식으로 컴퓨터에 대한 이야기부터 해보자.
컴퓨터는 여러 장치를 합쳐놓은 기계다. 본체 내부에도 여러 장치를 합쳐놓았고, 모니터, 키보드, 스피커, 마우스 등의 구성요소도 컴퓨터의 한 요소이다. 이들의 장치를 기능으로 분류하면 크게 다섯가지이다.
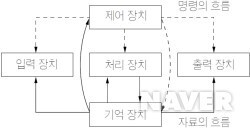
▶ 컴퓨터 구조
| 컴퓨터 구조 장치 | 장치 설명 | ||
| 입력장치 | 키보드 등과 같은 데이터를 컴퓨터에 입력할 수 있는 장치(ex. 키보드) | ||
| 출력장치 | 컴퓨터에서 외부로 정보를 출력하는 장치(ex. 프린터) | ||
| 중앙 처리 장치 (CPU) |
제어장치(control unit) | 기계 제어하는데 필요한 신호를 공급해주는 장치. CPU의 구성요소로 요구되는 마이크로 동작들을 연속적으로 수행하게 하는 신호를 보냄으로써 명령을 수행하게 한다. |
|
| 연산장치(ALU: Arithmetic and Logic Unit) | 컴퓨터의 작업을 수행하는 장치 | ||
| 기억장치 (저장장치) |
컴퓨터에서 사용하는 프로그램과 처리할 데이터, 결과를 저장하는 장치. 주기억장치, 보조기억장치, 캐시기억장치, 레지스터로 구분된다. |
||
| 주기억장치 (손) |
CPU와 직접 자료를 교환할 수 있는 장치이며, 기본적인 명령어와 데이터를 기억한다. 보조 기억장치보다 접근속도가 빠르고 순간적인 내용을 찾고 저장할 수 있다. RAM( Random Access Memory): 임시 기억 장치로, 휘발성 메모리이다. 찾는 자료 위치를 순차적으로 찾아가는게 아니라 어느 특정 위치에 직접 자료를 검색하고 저장하는 방법이다. CPU를 도와 명령 처리를 도와주며, 컴퓨터의 활동을 기억하고 있다가 다시 필요할 때 빠른 속도로 기억을 불러온다. (의사(CPU) 옆에 있는 레지던트(RAM) 느낌이랄까... 메스 요청하면 쥐어준다.) RAM 성능이 좋을수록 손이 많은 느낌이라 더욱 빠르다. 그래서 배그 같은 게임도 잘돌아감. ROM( Read Only Memory) : 읽기용 기억 장치로, 비휘발성 메모리이다. 컴퓨터의 전원이 끊어져도 내용이 유지되며, 컴퓨터 기본 운영 체제 기능이나 언어해석장치(interpreter)를 내장하고 있다. 내용 변경이 불가능해서 고쳐쓰거나 삭제할 수 없다. ROM은 컴퓨터 부팅할 때 어떤 순서로 켜지는지 저장되어있는데 이걸 불러와서 표시하는데 시간이 걸려서 부팅이 느린거임. 대표적인 예로 비디오게임 콘솔의 카트리지나, 전자기기의 시스템 메모리가 이에 해당한다. |
||
| 보조기억장치 (금고) |
CPU가 실행할 프로그램이나 데이터를 영구적으로 저장할 수 있는 장치. 주기억장치보다 속도는 느리지만 용량이 크고 비용이 저렴하다. 하드디스크, SSD, CD_ROM,DVD 등이 이에 해당한다. RAM과 다르게 순차적으로 저장된 데이터에 접근하기 때문에 하나하나 훑느라 주기억장치보다 속도가 느리다. | ||
| 캐시기억장치 (손 메모장) |
주기억장치에 저장되어있는 명령어와 데이터의 일부를 임시적으로 복사해서 저장해두고 있다가 빠르게 제공해주는 장치. CPU가 주기억장치에서 데이터를 처리할 때보다 빠르다. 둘 사이의 속도차이를 줄여주는 메모장과 같은 역할. 주기억장치가 메모리에 기억할 때 그 주소값을 복사해서 가지고 있으면 처음부터 뒤지지 않아도 바로 그 위치로 찾아갈 수 있게 도와주는 것.(메스 1-3 선반에 있어요!) | ||
| 레지스터 (선반) |
CPU 내의 고속의 기억 장치로, CPU가 연산 제어, 정보 해석 등의 요청을 처리할 때 필요한 데이터를 일시적으로 저장한다.  데이터를 아주 잠깐 거치해두는 선반이라고 생각하면 쉽다.(수술하다가 메스 두는 곳) 대부분 SRAM(손)이 데이터(메스)를 이리로 옮겨와 데이터를 처리하고 결과를 다시 SRAM(손)에 저장한다. |
||
▶ 메모리 계층 구조

컴퓨터의 설계 상 여러 종류의 저장장치들을 함께 사용해야 상황에 맞게 최적의 효율을 낸다. 하지만 빠른 저장장치는 용량에 비해 가격이 비싸고, 용량이 넉넉하면 속도가 느리기 때문에 싸고 성능 좋은 컴퓨터를 위해 이러한 메모리 계층 구조가 탄생하였다. 구조 설명은 위 내용을 참고하고, 한마디로 속도가 빠르고 비싼건 CPU와 가깝게 배치하고, 속도가 느리고 싼 저장장치는 CPU와 멀게 배치해서 적당한 가격으로 빠른 속도와 큰 용량을 얻을 수 있게 해준다. 대부분의 프로그램이 메모리의 작은 부분에만 자주 접근해서 사용되기 때문에 전체적인 성능이 향상된다.
▶ 그래서, 메모리란?
메모리는 보통 기억장치에 있는 주기억장치, 특히나 RAM을 의미한다. 프로그램을 구동하기 위해서 운영체제가 메모리(RAM)에 데이터 및 명령어를 저장할 공간을 할당하여 준다.
프로그램은 하드디스크 등의 보조기억장치에 저장된 실행코드를 뜻하고, 프로세스(process)는 프로그램을 구동하여 메모리 상에 실행되는 작업단위이다. 하나의 프로그램을 여러번 구동하면 여러개의 프로세스가 메모리(RAM) 상에서 실행되는 것. 프로세스 여러개가 있으면 각각의 메모리 공간이 있으며 원칙적으로 서로 다른 프로세스간의 메모리 공간 접근은 허용되지 않는다.(만약 접근하려면 프로세스간 통신이 필요)

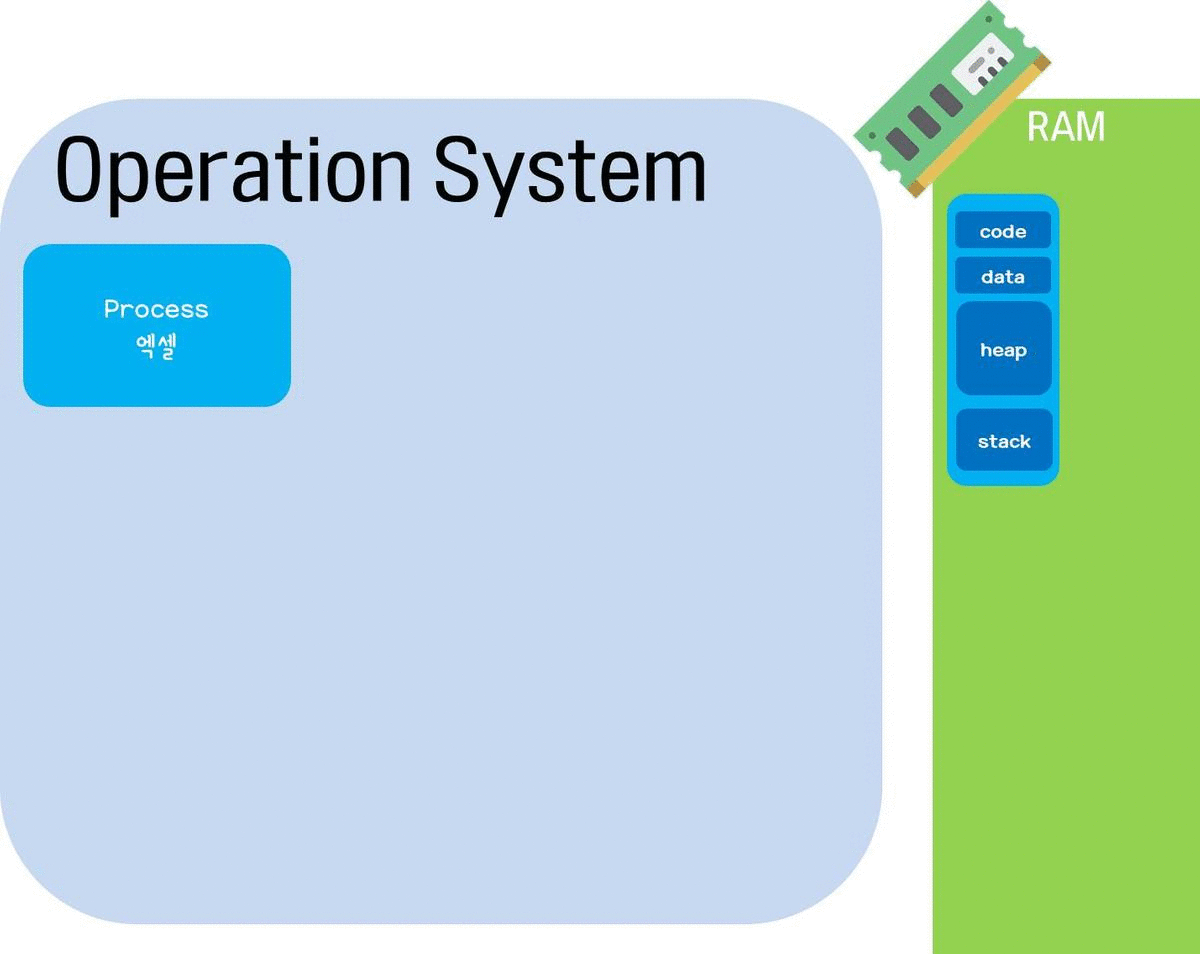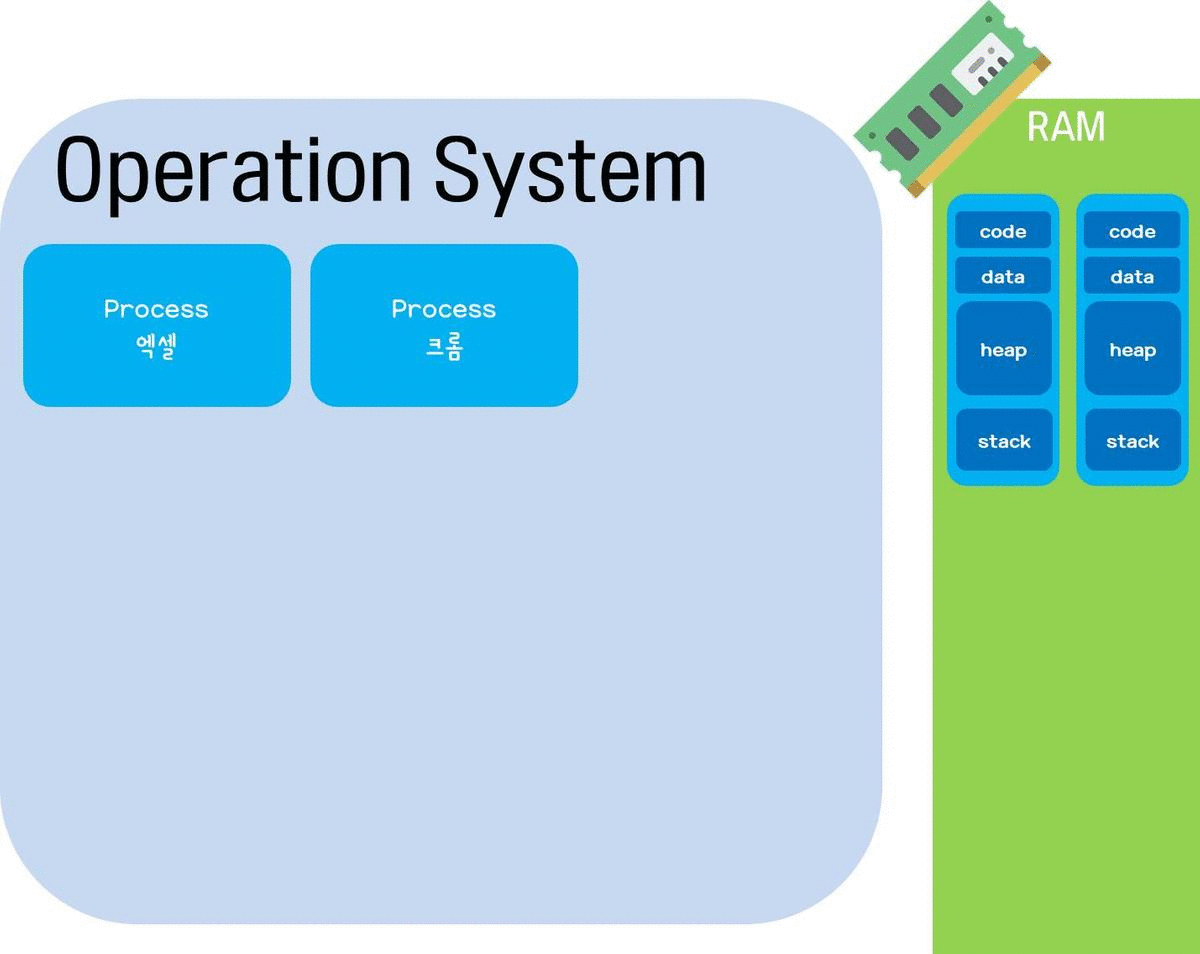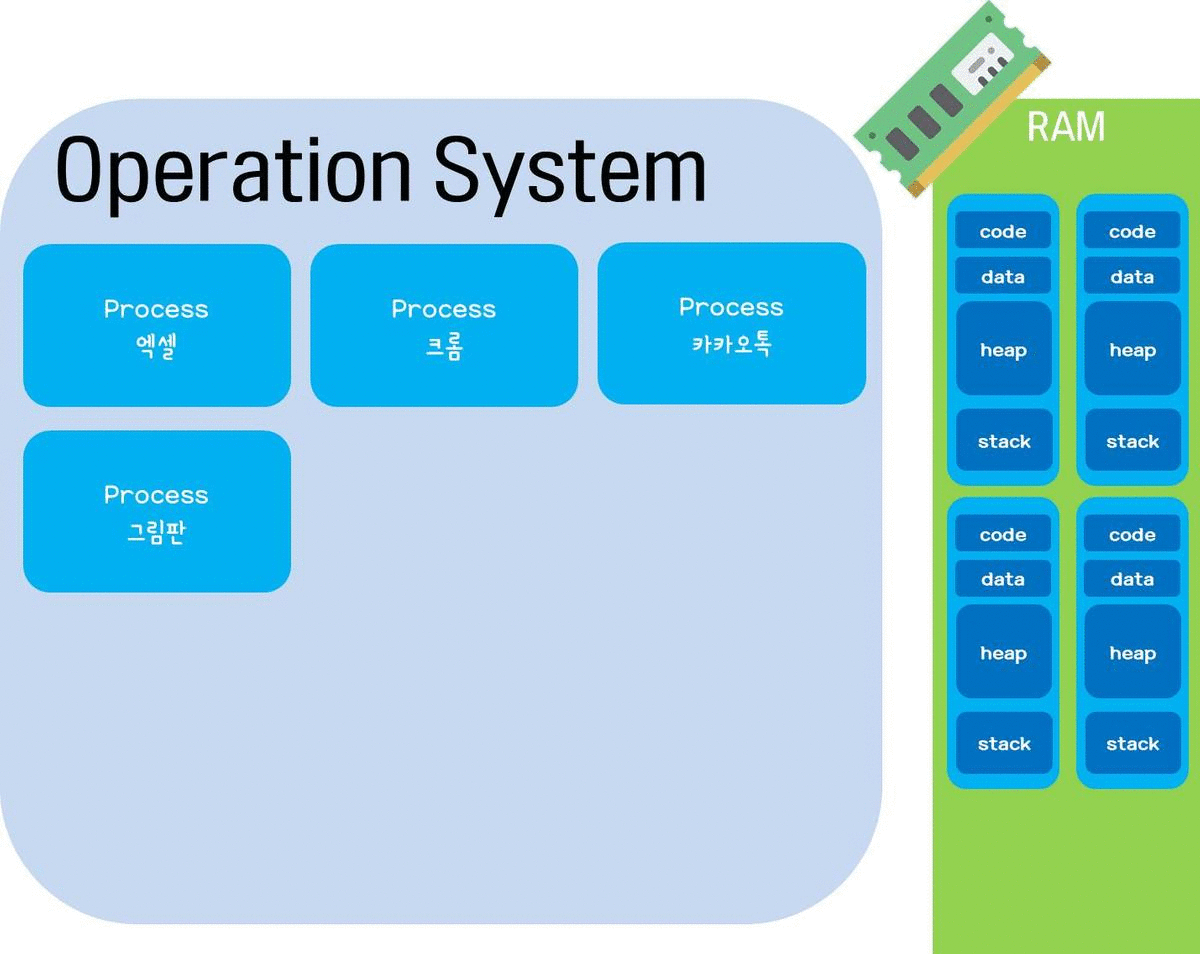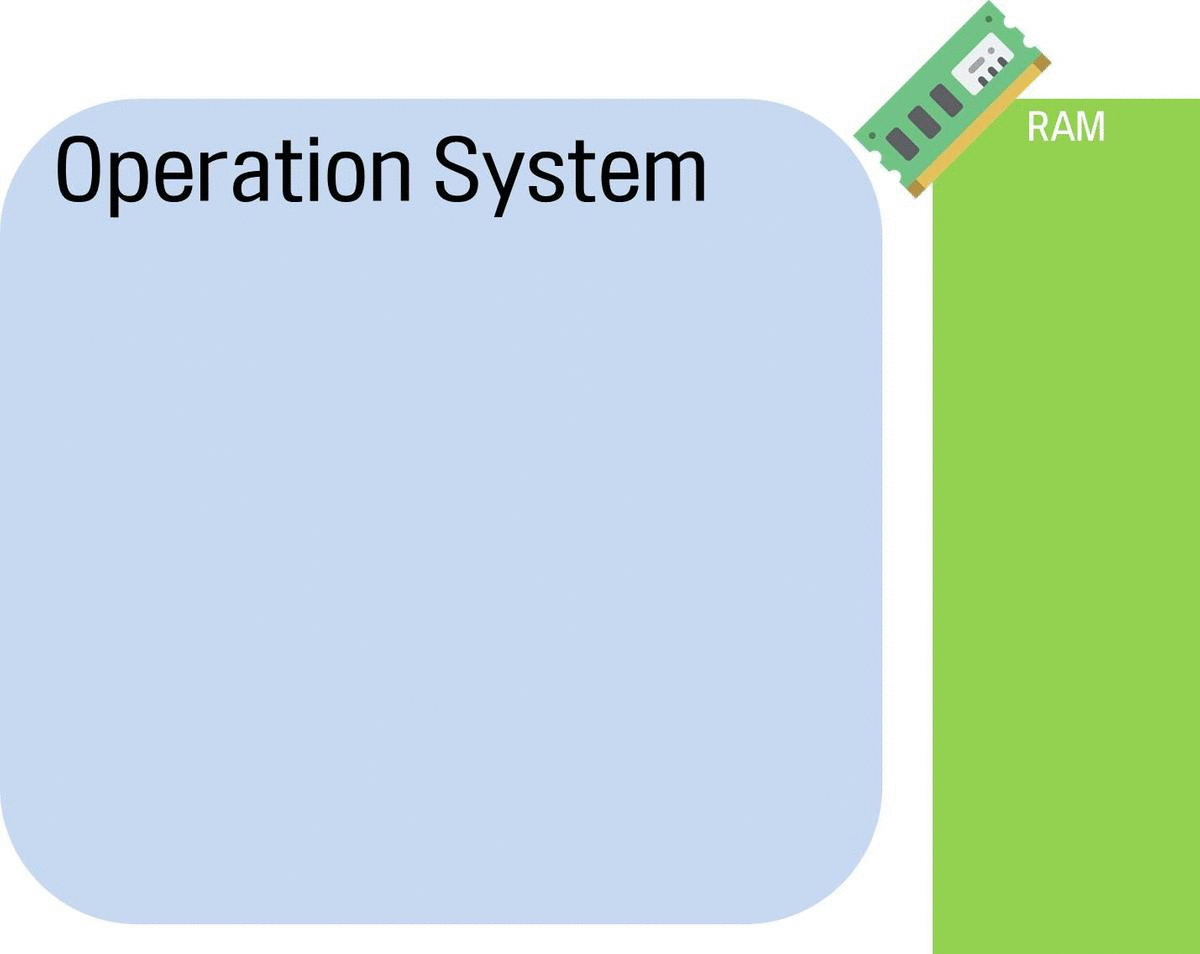
원래 CPU(=프로세서)는 한순간에 하나의 프로세스만 실행할 수 있다. 쉽게 말해 CPU는 한 사람이라서 한순간에 동작을 하나만 할 수 있는 것. 근데 어떻게 여러개의 프로세스가 메모리상에 실행될 수 있을까? 바로 CPU가 처리하는 시간을 잘게 쪼개서 여러 프로세스에 배분하는 방식으로 동작하기 때문이다. (이를 시분할 시스템(Time Sharing System)이라고 한다.) CPU가 첫번째 프로세스를 실행하다가 입/출력 등 때문에 대기상태가 되면 곧바로 다른 작업을 하다가, 대기상태가 끝나면 첫번째 프로세스로 다시 돌아와서 작업하는 방식으로 쪼개서 여러 일을 동시에 수행한다. (그리고 프로세스가 대기상태인 것을 다른 프로세스들에게 알려주고, 작업을 마저 도와줄 수 있도록 하는 프로세스 내부의 세포(?)의 이름이 스레드(Thread)이다.)
메모리는 컴퓨터에게 있어 가장 중요한 자산이고 사용할 수 있는 공간이 한정되어 있기 때문에 어떻게 관리하느냐에 따라서 프로그램의 성능(속도 등)이 좌우된다. 손(=프로세스)의 구조가 어떻게 구성되어있느냐에 따라 효율이 다를테니까.
따라서 메모리를 효율적으로 사용하기 위해서는 메모리의 구성과 특징에 대해서 이해할 필요가 있다.
프로그램의 실행되어 프로세스 메모리 영역에 자리를 잡고 움직이기 시작하면 어떤 일이 벌어질까?
▶ 프로그램의 실행(프로세스)과 메모리 영역
프로그램이 실행되기 위해서는 운영체제(OS)가 프로그램의 정보를 메모리에 로드해야 한다. 또한 프로그램이 실행되는 동안 CPU가 코드를 처리하기 위해서는, 메모리가 명령어와 데이터들을 저장해야 한다. 이와 같이 프로그램을 실행하기 위해 프로세스가 실행되면 운영체제(OS)는 프로그램 실행을 위해 각각의 독립된 메모리 공간인 코드, 데이터, 스택, 힙을 할당한다. 이러한 주소 공간을 가상메모리(또는 논리적 메모리 : logical memory)라고 부른다.
아래는 프로세스가 프로그램 실행을 위해 점유한 메모리 영역을 나눈 것이다.
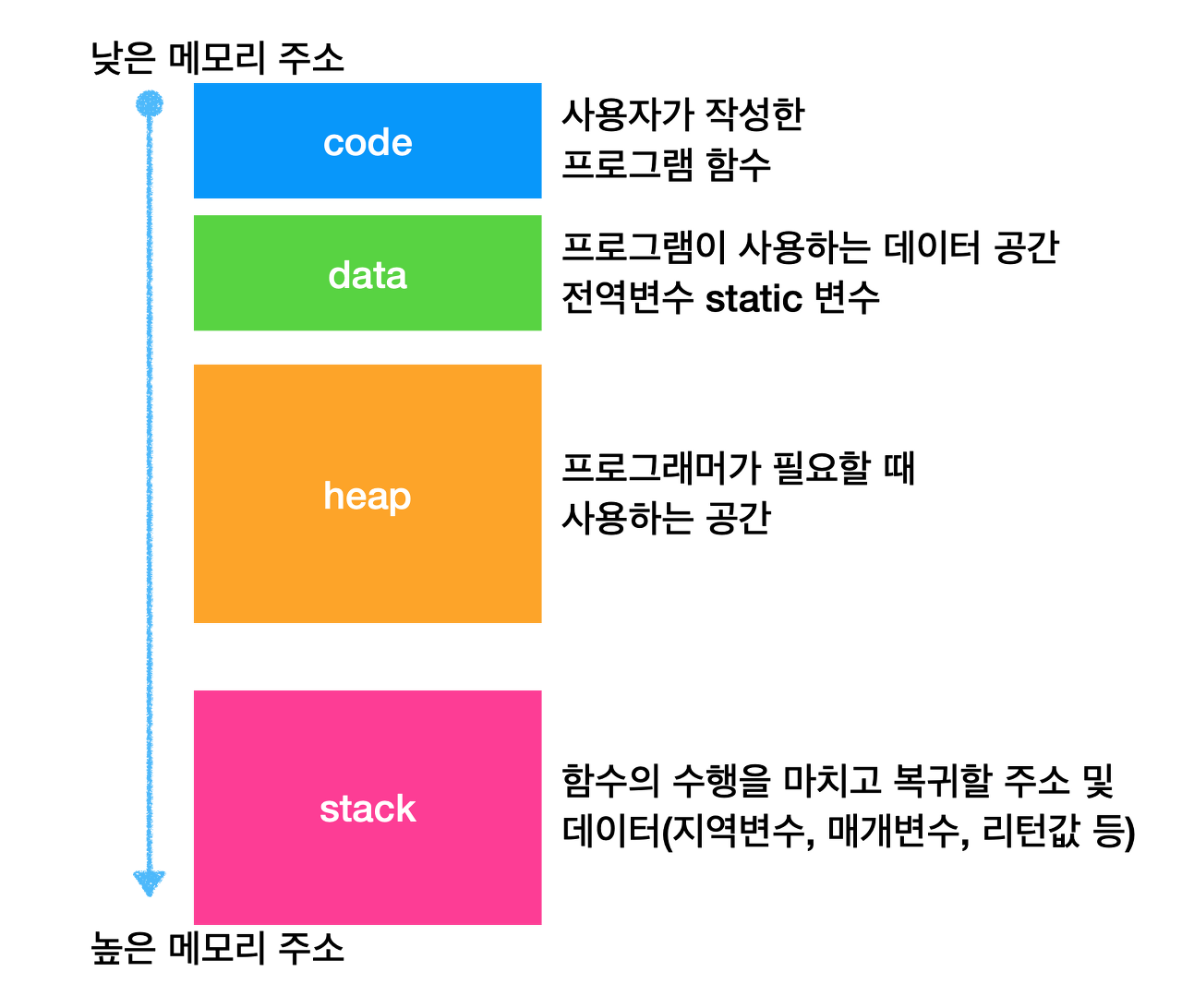
찬찬히 뜯어보면 다음과 같다.
| 프로세스 주소 공간 | 설명 |
| code 영역 (Text 영역) |
실행할 프로그램의 코드가 저장되는 영역이다. 사용자가 작성한 프로그램 함수들의 코드가 CPU가 읽을 수 있는 기계어 형태로 변환되어(=컴파일타임(Compiletime)을 거침) 저장되어있음. CPU는 code 영역에 저장된 명령을 하나씩 가져가서 처리한다. 중간에 바꿀 수 없게 Read-only 로 되어 있다. |
| data 영역 | 전역 변수 또는 static 변수 등 프로그램이 사용하는 데이터가 저장되는 영역이다. 전역 변수 또는 static 값을 참조한 코드는 컴파일이 완료되면 data 영역의 주소값을 가르키도록 바뀐다. 그래서 주소값으로 데이터를 찾아가는 것. 전역변수가 변경 될 수도 있어 Read-Write로 되어있다. |
| heap 영역 | 프로그래머가 필요할 때마다 직접 공간을 할당, 해제하여 사용하는 메모리 영역이다. heap 영역은 컴파일 후 응용프로그램이 동작하는 런타임(Runtime)에 결정된다. heap 영역에서 malloc()또는 new 연산자를 통해 메모리를 할당하고, free() 또는 delete 연산자를 통해 메모리를 해제한다. 선입선출(FIFO, First-In First-Out)의 방식으로, 가장 먼저 들어온 데이터가 가장 먼저 인출 된다. 메모리의 낮은 주소에서 높은 주소의 방향으로 할당되기 때문이다. (자바에서는 객체가 heap영역에 생성되고 GC에 의해 정리된다.) |
| stack 영역 | 프로그램이 자동으로 사용하는 임시 메모리 영역이다. 호출된 함수의 수행을 마치고 복귀할 주소 및 데이터(지역변수, 매개변수, 리턴값 등)를 임시로 저장하는 공간으로, 함수 호출이 완료되면 사라진다. stack 영역에서 푸시(push) 로 데이터를 저장하고, 팝(pop) 으로 데이터를 인출한다. 후입선출(LIFO, Last In First Out) 방식으로, 가장 나중에 들어온 데이터가 가장 먼저 인출 된다. 메모리의 높은 주소에서 낮은 주소의 방향으로 할당 되기 때문이다. 컴파일 시 stack 영역의 크기가 결정되기 때문에 무한정 할당 할 수 없다. 따라서 재귀함수가 반복해서 호출되거나 함수가 지역변수를 메모리를 초과할 정도로 너무 많이 가지고 있다면 stack overflow가 발생한다. |
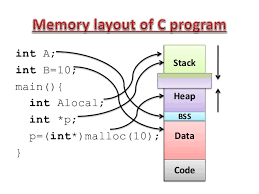
이 그림이 잘 설명되어 있어서 가져와봤다.
코드(Text)는 code 영역에 저장되어 있고, 이 코드를 실행할 때 잘 뽑아쓸 수 있게 영역마다 나눠놓는것이다.
data 영역에서는 전역변수(모든 지역에서 접근가능), static 참조 변수와 같이 다 가져다쓸 수 있는 데이터를 넣어놓는다. 얘네는 주소값만 가지고 있으면 모두 찾아갈 수 있고, 덮어쓸 수 있으니 수정도 가능하다.
stack 영역은 함수 내에 할당된 지역변수(해당 지역에서만 접근가능)들을 넣어놓는다. 임시 메모리 영역이라는 이유는 함수가 끝나면 그 지역을 벗어났으므로 저장되었던 지역변수들은 없어지기 때문이다. 이 모든 과정은 컴파일러에 미리 정의되어 있는 루틴을 통해 수행해서 자동으로 되므로, 프로그래머가 신경쓰지 않아도 된다.
Heap 영역은 프로그래머가 작성한 명령을 수행중에 메모리가 차곡차곡 쌓아올려(heap) 할당되는 곳이다. new 연산자를 쓰면 Heap 영역의 메모리 공간에 자리를 만들어주고, 만들어진 객체, 배열 등을 그곳에 저장한다. 이곳에 저장된 값을 곧바로 꺼내 쓰는게 아니라 그 공간의 주소값을 new 연산자를 통해 리턴받는다. 이렇게 되면 실제 데이터는 Heap 영역에 있는데, 그게 어디있는지 알려주는 주소값(참조값)을 stack 영역의 객체가 가지고 있는 것이다.
▶ 오버플로우(Overflow)

오버플로우는 말 그대로 넘쳐 흐른다는 말이다.
한정된 메모리 공간이 부족해서 데이터가 넘친다는 의미로, 힙의 경우에는 낮은 주소에서 높은 주소로 할당되고, 스택의 경우에는 높은 주소에서 낮은 주소로 할당되어 서로의 영역을 침범할 수 있다. 이때 힙이 스택 영역을 침범하는 경우를 힙 오버플로우, 스택이 힙 영역을 침범하는 경우를 스택 오버플로우라고 한다.
변수의 타입과 관련해서도 오버플로우가 발생할 수 있다.
- Overflow (오버플로우) : 메모리의 표현 범위에서 벗어난 수의 값을 저장하는 경우
- Underflow (언더플로우) : 메모리가 표현할 수 있는 수보다 적은 수의 값을 저장하는 경우

Python과 같은 동적언어는 런타임 시 자동으로 변수의 타입이 지정되기 때문에 함수가 매개변수를 받을 때에 자료형을 따로 지정하지 않는다. 반면 Java는 '정적언어'로 컴파일할 때 변수의 타입이 결정되기 때문에, 변수를 선언할 때에는 자료형을 별도로 지정해주어야 한다. (Java 외에도 C언어 또한 변수 타입을 지정해주어야 하는 정적언어)
약간 비유적으로 말하자면... 컴퓨터는 "이거 정수야!" 라고 말해주고 "이거 실수야!" 라고 말해주어야 그렇게 읽는다. int(32 비트) 기준으로 보면
| 사람 : "이거 정수야!" 컴퓨터 : "정수라는 것은 32 비트로 -2^31 ( -2147483648 )에서 2^31 -1 ( 2147483647 ) 사이의 값을 할당 할 수 있습니다. 이 사이의 값으로 인식합니다." |
라고 하는 것이다.
근데 정수라고 말해놓고 정수보다 더 큰 값을 넣는다고 생각해보자. 그럼 32비트보다 넘기 때문에 남은 비트가 "넘쳐흐르게 된다."
▶프로세스의 상태(status)
CPU가 여러 작업을 동시에 하는 것 처럼 보이는 이유는 쪼개서 일하기 때문이라고 했다.첫번째 프로세스를 실행하다가 입/출력 등 때문에 대기상태가 되면 곧바로 다른 작업을 하다가, 대기상태가 끝나면 첫번째 프로세스로 다시 돌아와서 작업하는 방식으로 쪼개서 여러 일을 동시에 수행한다. 이 프로세스의 상태는 크게 실행(Running), 준비(Ready), 봉쇄(Blocked || Waiting || Sleep) 세 가지로 분류된다.
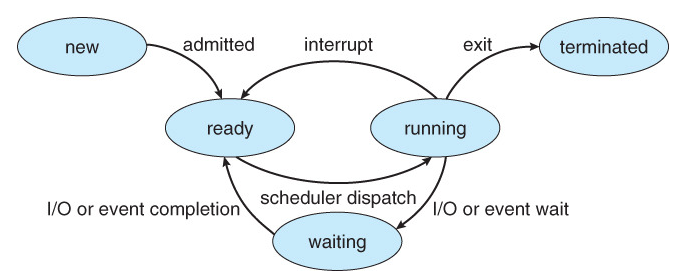
new : 프로세스 생성 상태
ready : 프로세스 할당 대기 상태
running : 프로세스의 명령어를 실행 중인 상태
waiting : 프로세스가 어떠한 이벤트가 일어나는 것을 기다리는 상태
terminated : 프로세스가 종료된 상태
- Admitted [생성 -> 준비] : 준비 큐가 비어있을 때 작업 스케줄러에 의해 실행
- Dispatch [준비 -> 실행] : 스케줄러에 의해 준비 큐 맨 앞에 있는 프로세스에게 CPU를 할당
- Blocked [실행 -> 대기] : CPU를 할당받은 프로세스가 입출력 작업등으로 인해 명령을 실행할 수 없는 상태
- Wake up [대기 -> 준비] :block상태의 프로세스가 입출력 작업이 끝나면 대기 상태에서 준비 상태가 됨
- Interrupt [실행 -> 준비] : Timer run out, CPU를 점유 중인 프로세스가 할당된 시간을 모두 사용하여 타임 아웃되거나, CPU 스케줄링 정책에 따라 우선순위가 높은 프로세스로 CPU 디스 패치된 상태
- Exit [실행 -> 종료] : 프로세스가 CPU를 할당받아 작업을 모두 수행한 상태
▶문맥 교환(Context Switch)
상태가 입력/출력 상태라면 이걸 다른 프로세스에게 전달해주어야 끊김 없이 CPU가 일하겠지? 문맥 교환(Context Switch)란 하나의 프로세스로부터 다른 프로세스로 CPU 제어권이 이양되는 과정을 뜻하는데, 이러한 과정을 CPU 디스패치(Dispatch)라고 한다. 어떠한 프로세스가 CPU를 할당받고 실행되는 도중 인터럽트가 발생하면 CPU의 제어권은 운영체제로 넘어가게 되고 타이머 인터럽트 처리 루틴으로 가서 수행 중이던 프로세스의 문맥을 저장하고 새롭게 실행시킬 프로세스에게 CPU를 이양한다. 하지만 프로세스 간 문맥 교환이 빈번하게 발생 시에는 오버헤드가 발생할 수 있다.
따라서 프로그램 실행 순서는 아래와 같다.
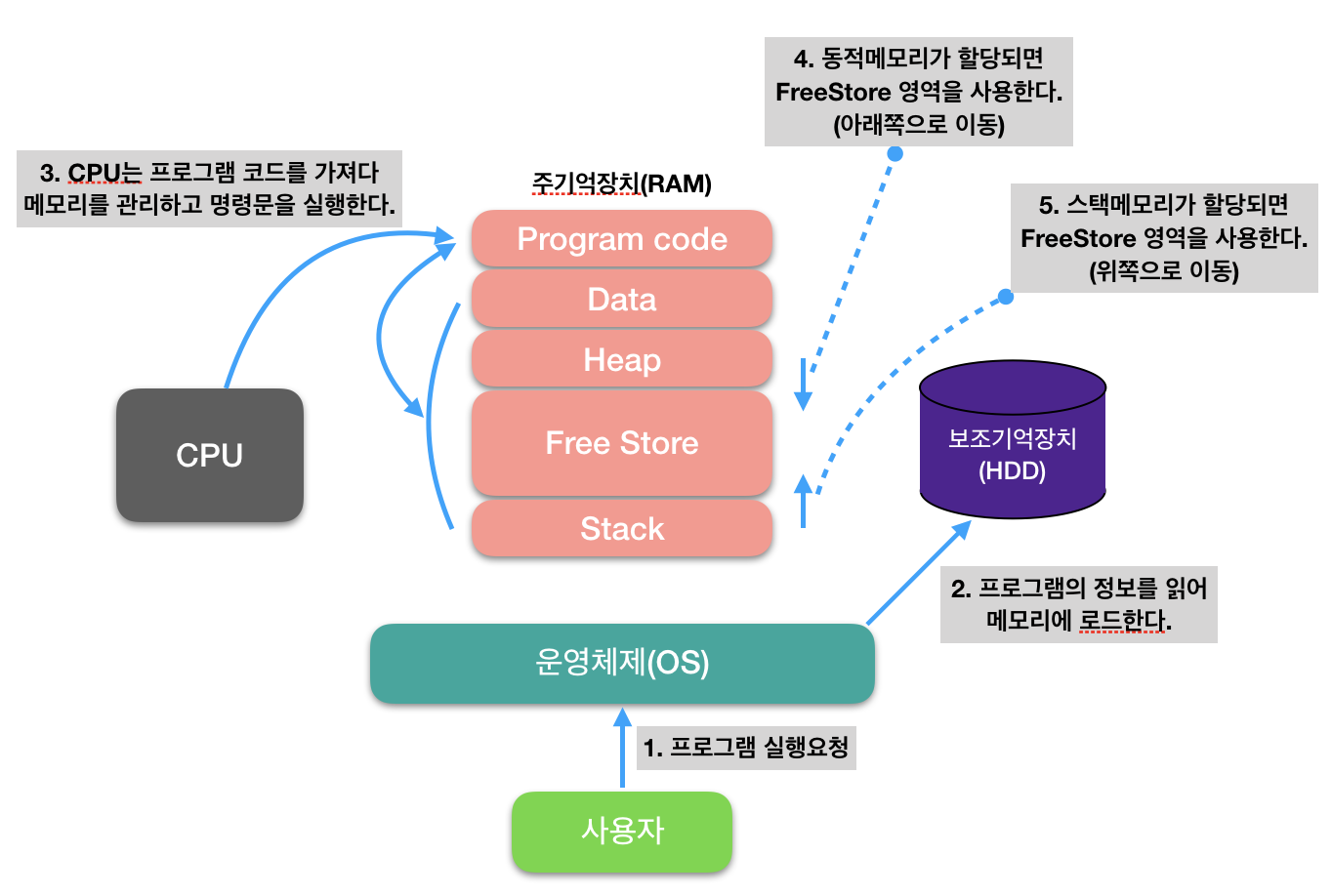
약간씩 차이는 있겠지만 대부분 RAM이라는 주기억장치, 즉 메모리에서 프로그램을 수행하기 위해 프로세스 별로 데이터를 나누고 가공하고 기계어로 번역하는 등의 일을 진행한다.
'[ 개발 지식 ]' 카테고리의 다른 글
| 일반인에게 설명하는 [자바 프로그램의 실행 과정] - 2. 자바 프로그램 실행 (0) | 2022.09.19 |
|---|---|
| 일반인에게 설명하는 [자바 프로그램의 실행 과정] - 1. 프로그램 실행 (2) | 2022.09.19 |
| [JS] 협업 툴 개념 및 정리 - node.js 패키지 툴(npm, yarm, brew) / Git 클라이언트 프로그램(Fork, Gitlab, gitbash) (0) | 2021.03.08 |
| [java] 면접 전 다시 보면 좋을 블로그 모음 (0) | 2020.12.08 |
| 개발자 면접 준비 중 헷갈릴만한 단어 정리 (0) | 2020.11.16 |