복습 : 한국전력공사 용어사전에서 검색 후 텍스트 출력하기
0. Main.xaml > Flowchart 생성 > Sequence 생성
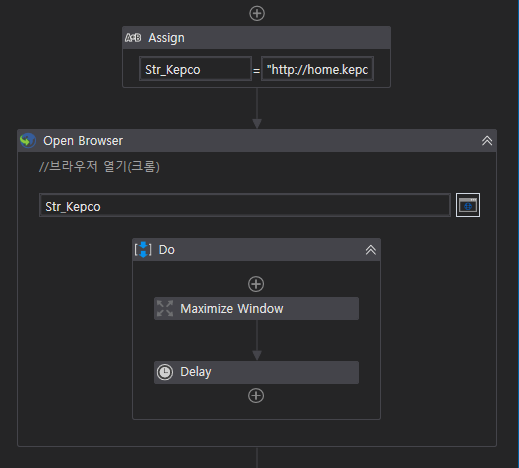
1. 브라우저 열기 : (Assign 변수선언) - Open Browser - [ Maximize Window - Delay ]
크롬 설정 빼먹지 말고 할 것!
보통 URL이나 아이디/비밀번호 입력하는 것들은 변수처리 해놓는게 맞다!
2. 카테고리 클릭 : Attach Browser - [ Click ] - Delay
한국전력공사(main page) > [지식센터] > [전력용어] > [KEPCO 용어사전]


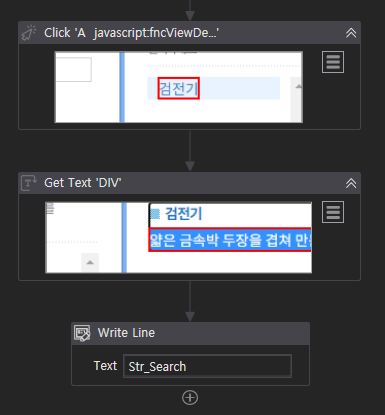
3. 선택박스 고르기 : Click(선택박스) - Select item - 원하는 것 선택

4. 텍스트 입력 후 검색 : Type Into - [ 변수선언 및 value 값 입력 ] - Click
변수 선언 shift + k

5. 텍스트 가져오기 : Click - Get Text(가져오고) - Write Line(출력)
가져올 내용을 변수선언 후 담아서 출력했다.
브라우저 액티비티
1. 브라우저 이동하기 : Navigate to
해당 사이트로 이동합니다. 빈칸에 웹페이지 주소를 적습니다.
2. 탭 닫기 : Close Tab
브라우저를 닫는다. 이동과 닫는 것은 함께 쓸 수 없다. 다른 attach로 해야한다.

스크린 스크랩핑
- 미리보기 기능을 지원하지만 write Line은 불가
- 리본메뉴를 쓰면 자동으로 Attach Browser가 생성된다. -> 따로 안써도 됨
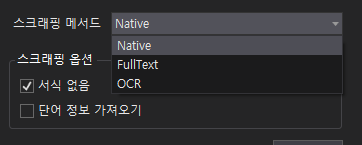
- 스크림 스크랩핑의 메서드
- Native : 원본 모양 그대로(줄바꿈 포함)
- Full Text (=Get Text 와 기능동일) : 텍스트 전부, 필요없는 텍스트까지
- OCR -> 이미지 글자 추출

- 스크래핑을 할 때에 고려할 점
- 공백은 어떻게 하는지?
- 이미지만 가져올껀지
- 텍스트만 추출할건지? -> Full text는 여러 요소가 섞여있기 때문.
- 단, 숨겨진 항목 무시하기 누르면 아래 텍스트는 생략
- Full text는 key값이 함께 와서 키-값 매칭해서 가져오기 편하다.
- 개발자들은 이 이후 진행할 '데이터 가공' 단계에 어떠한 데이터가 필요할지 판단 후 가져온다.
1. 원하는 영역 선택 : 리본메뉴 - 스크린 스크래핑 - 원하는 영역 선택


Native로 받아오자. 글씨가 공백 없이 깔끔하게 받아와진다.

2. 텍스트 출력 : write Line
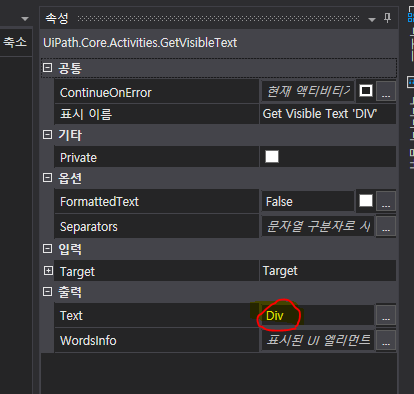

[ 에러 ] RemoteException wrapping System.Runtime.InteropServices.COMException 메시지 : 캡처 오류입니다.
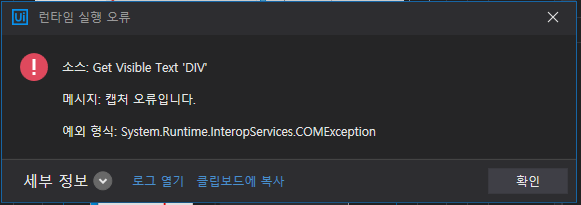
스크린 스크래핑은 보이는 화면에서 그 위치를 그대로 가져온다.
따라서 실행시킬 때 스크래핑 하는 스크린을 띄워놔야한다.
에러가 난 이유는 스크래핑 창이 아닌 다른 탭을 띄워놨기 때문이다.
형변환
해당 데이터의 타입을 바꿔주는 것. 우리가 받아온 데이터의 비교 및 연산을 하기 위해서 사용된다. 연산을 위해서는 기본적으로 숫자여야 한다. 따라서 형변환이 필요하다.
+ 보통 데이터를 추출하면 Generic value 형식으로 뽑힌다. (Generic value : 모든 데이터를 다 포함하는 상위 형식)
ex) 스크린 스크래핑, get text로 받아온 String 등
++ 현장에서 count 쓸 때에는 int를 쓰지만 보통 Double를 쓴다. 모든 숫자는 대부분 Double로 설정하자. int32보다 Double이 범위가 훨씬 크다.
+++형변환 사용 예시 : 재무,회계,인사(HR) 관련 프로젝트를 진행할 때 (= 돈관련) 이때는 형변환을 반드시 사용한다.
text 형변환은 이미 배웠다. : .ToString 을 사용하면 text를 형변환 한다. 텍스트 가공(뒤에 나올 String 메소드 사용) 시에 사용한다.
숫자를 형변환 할 때는 cdbl(generic ~~) 을 사용한다. 연산을 위해 사용된다.
1. 브라우저에서 환율 긁어오기 : Attach Browser - [ Get text - Write Line - If ]
환율을 긁어왔지만 이건 String으로 가져온 것이다. 따라서 비교연산자를 사용하기 위해 cdbl(변수명) 을 사용한다.

파일 디렉토리
원래 it에는 디렉토리라는 함수가 있다. System.IO 라는 함수들이 있는데, 파일, 폴더 등을 관리를 해주는 함수를 디렉토리라고 한다.
예를 들면 폴더에서 폴더(또는 파일)를 이동할 때에는 \(역슬래쉬)를 사용한다. 그리고 파일은 뒤에는 항상 확장자명이 함께 붙는다. 디렉토리는 항상 파일확장자명을 가지고 있다.
현재 우리가 가지고 있는 파일의 경로는 다음과 같다.
"C:\RPA_Guidebook\Session5_UI 데이터 추출하기\Result\Expert.xlsx"
이러한 경로를 Full Path, 전체경로라고 한다. 항상 뭔가를 실행할때는 전체 경로 뒤에 파일과 파일 확장자까지 붙여서 (전체 경로를 써서) 실행한다. 윈도우에서는 파일 다운로드 하거나, 복사 등등을 많이 쓴다. 그때 Full Path를 많이 사용한다.

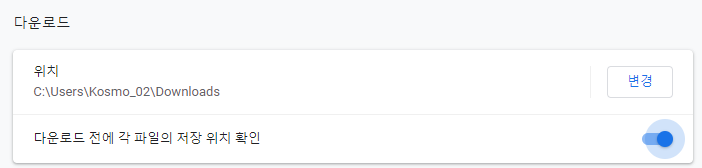
[주의] 파일 저장 위치 확인
파일 다운로드 받을 때 각 파일의 저장 위치를 지정해주는 것이 중요하다. 항상 다운로드 폴더에 저장 크롬에서 설정 > 고급에서 체킹 꼭 해준다. 현장에 나가서도 꼭 바꿔줘야한다.
[ 파일 확장자명 총정리 ]
1. 엑셀 : .xlsx(기본) .xls
2. 파워포인트 : .pptx
3. 워드 : .doc /.docs
4. PDF : .pdf
5. 텍스트파일 : .txt
6. csv 파일 : .csv
7. zip 파일 : .zip
8. 그림 파일 : .jpg / .png
+ 과제 157p
여기까지 데이터 추출 단계 끝
참고 꿀팁
1. target 속성
target 옆에 +를 누르면 Timeout를 설정할 수 있다.
selector는 xml 의 필요한 부분을 가져온 것.
NextLinkSelector는 다음페이지 넘어가는 버튼 표시해주는 것.

2. 실행키 : window + r
3. 파란색 느낌표 : 에러표시
느낌표가 떠서 에러가 나면 가장 아래꺼 보면 뭐가 문제인지 알 수 있다. 가장 아래 있는 파란 느낌표가 원인데이터이므로 거기를 살펴보자.
4. 배열과 컬렉션
배열은 크기선언이 필수 -> 크기 선언 후 assign을 해서 값을 넣어줌
컬렉션 타입의 list의 경우 자동으로 카운트 되며 assign이 아닌 Add to Collection을 사용한다.
둘다 For Each를 사용해서 한다.
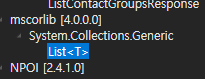

셀렉터(Selector)
UI 속성값을 저장한 표준 XML 코드. 현재 표시한 화면에 대한 정보를 표시한 것이다.

여기서 강조표시를 누르면,

Selector는 에러메시지 확인할 때 유용하다.
1. 사이트의 화면이 변경되었을 경우
2. 사이트 자체가 없어졌을 경우
3. 창 크기가 달라 인식을 못할 경우
이렇게 ui가 변경되거나 없어진 경우 Selector를 이용하면 확인할 수 있다.
유효성 검사 상태
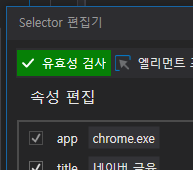
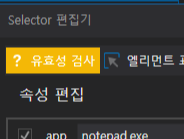
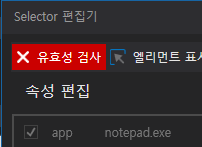
유효성 검사는 각 색깔별로 UI의 상태를 확인할 수 있다.
- 초록 : 해당 UI가 화면에 있다.
- 노랑 : 아직 실행이 되지 않았거나 아직 알 수 없는 상태. 눌러보면 초록인지 빨강인지 알 수 있다.
- 빨강 : 해당 UI가 화면에 없다.
와일드카드(*)
메모장을 틀어놓고 자동으로 입력되는 간단한 시퀀스를 만든다.
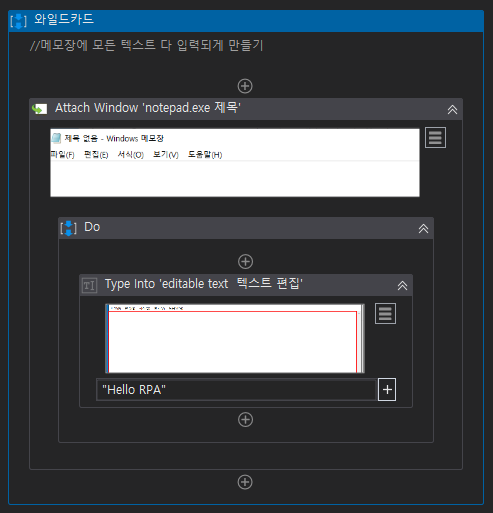
이때 Selector를 살펴보면 다음과 같다.

이제 이미 실행한 시퀀스를 한번더, 총 두 번 실행한다.
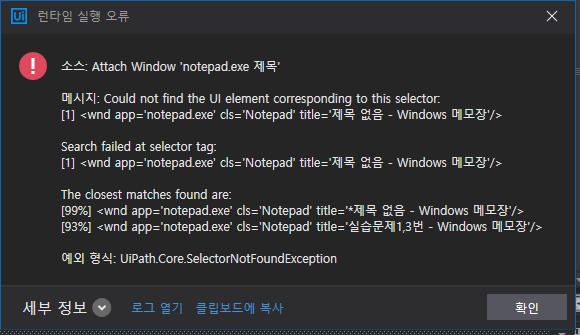
에러가 난다. 왜?
메모장을 살펴보자.
이름이 바뀌었다. * 표시가 붙는다.(수정되고 있음을 표시) 아까 attach Window로 지정한 창이 아니게 된 것.
즉, 제목이 달라서 에러가 남.

이럴 때 와일드카드가 사용된다.
[ 와일드카드 ]
하나 또는 둘 이상의 문자를 대체하는 기호. 주로 Selector에서 속성을 변경할 때 사용된다.
? : 문자 1개를 대체한다.
* : 0개 이상의 문자를 대체한다.
즉, 자주 변경되는 UI(이름, 날짜 등이 포함된 제목)에 대해 에러가 발생하지 않도록 처리해준다.
와일드카드를 이용해서 Selector의 제목을 변경해주어서 에러를 없애보자.

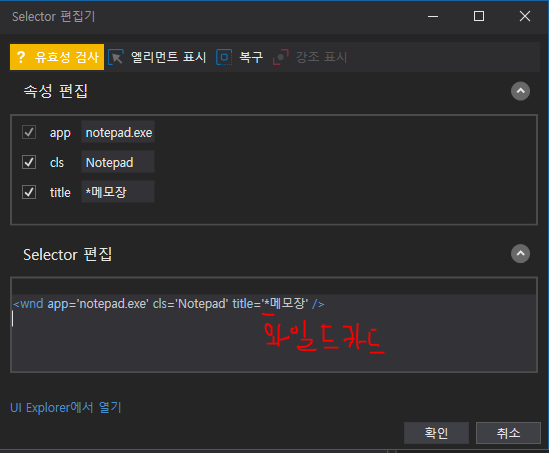
다시한번 실행해보면,

->수정을 뜻하는 * 표시랑 다른거다.
언제 와일드카드를 쓸까?
공통모듈(프로세스)를 만들 때 사용한다.
- 사이트 검색창에 검색어를 입력하는 프로세스
- 사이트 이동하는 프로세스(Navigate to)
와일드카드는 attach browser 또는 attach window의 title 또는 name 태그를 수정할 때 쓰인다.
'[ RPA ]' 카테고리의 다른 글
| [RPA] Ui Path - 딕셔너리(Dictionary) 정보보안 (0) | 2020.11.13 |
|---|---|
| [RPA] Ui Path - RPA 프로젝트 절차 / 객체지향방식 (Invoke workflow) (0) | 2020.11.11 |
| [RPA] UI Path 액티비티 정리 (4) | 2020.11.09 |
| [RPA] 기능(1) - 조건문 / 로그인 기능 만들기 / 데이터 스크래핑 (0) | 2020.11.06 |
| [ RPA ] UI PATH 설치 (0) | 2020.11.06 |