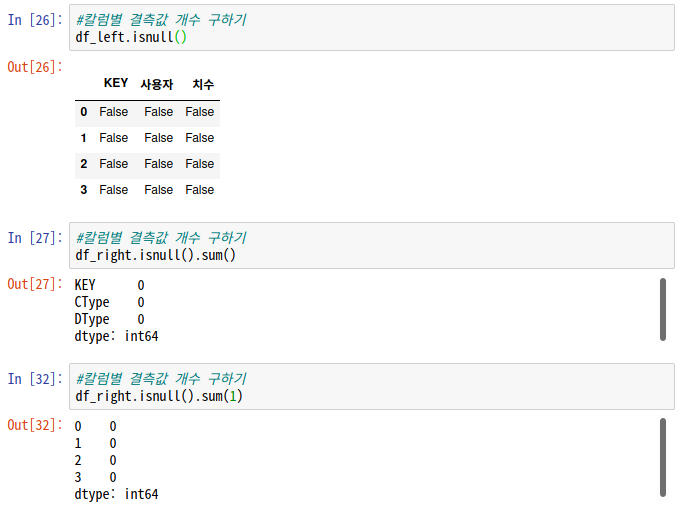
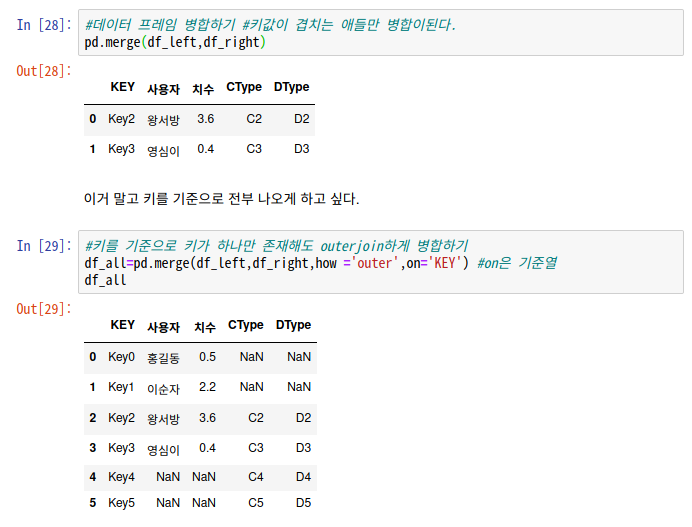
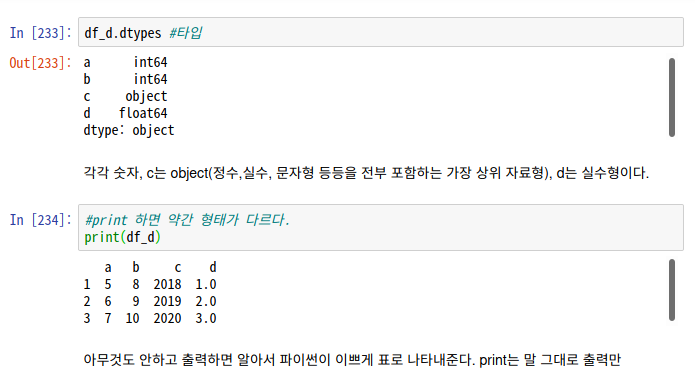
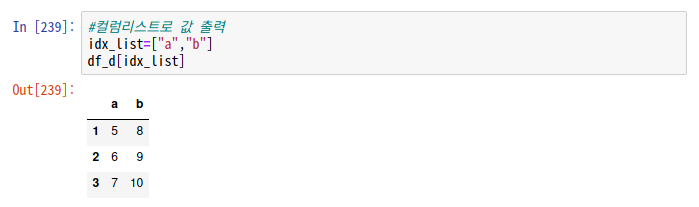
1. 외부데이터 수입해서 다루기(복습)

2. Group by : groupby(by=[묶는기준], as_index=False )
한개열 또는 여러열을 기준으로 집계하는 함수.
집계하고자하는 열 이름을 by 파라미터에 입력하고 호출하면 된다.
as_index=False : 인덱스 손질. 설정하지 않으면 판다스(Pandas) 복합 인덱스로 올라가서 변환하거나 사용하기 어렵다.
1) 한개 열을 기준으로 집계하기
df = pd.DataFrame({
'상품번호':['상품1','상품2','상품3','상품4'],
'수량' : [2,3,5,10]
})
df
기본적으로 groupby만 해도 이미 집계는 되어있는 상태이다.
단, generator 상태이기 때문에 추가적으로 산술통계를 써서 원하는 값을 도출하는 방식으로 쓰인다.
#상품번호별로 묶기, 인덱스 손질하는 코드 추가
df.groupby(by=['상품번호'],as_index=False)
다양한 산술통계를 써서 결과를 보자.
# min: 상품번호별 판매된 총수량
df.groupby(by=['상품번호'],as_index=False).sum()
# min: 상품번호별 판매된 최소 수량
df.groupby(by=['상품번호'],as_index=False).min()
# min: 상품번호별 판매된 최대 수량
df.groupby(by=['상품번호'],as_index=False).max()
# mean: 상품번호별 판매된 평균 수량
df.groupby(by=['상품번호'],as_index=False).mean()
#count : 상품번호별 판매 수
df.groupby(by=['상품번호'],as_index=False).count()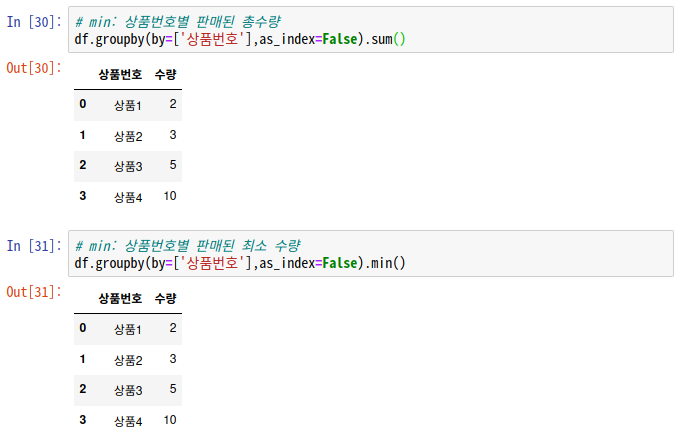


2) 여러 열을 기준으로 집계하기
import pandas as pd
df = pd.DataFrame({'고객번호' : ['고객1', '고객2', '고객3', '고객4'],
'상품번호':['상품1','상품2','상품3','상품4'],
'수량' : [2,3,5,10]})
[연습문제] 연도를 그룹으로 해서 지역명이 경기만 그룹화해서 총 갯수를 그룹별로 출력하기
오라클 식으로 풀면 select count(*), 연도 from apt where 지역명=='경기' group by 연도
#지역명이 경기인 것만 연도별로 그룹화해서 슬라이스한다.
aptGroupby = aptData.loc[aptData.지역명=='경기'].groupby(['연도'],as_index=False)
#그거 총 갯수 세서 다시 aptGroupby에 넣줌
aptGroupby=aptGroupby.count()
aptGroupby
#거기서 연도와 지역명만 가져오기
aptGroupby[['연도','지역명']]
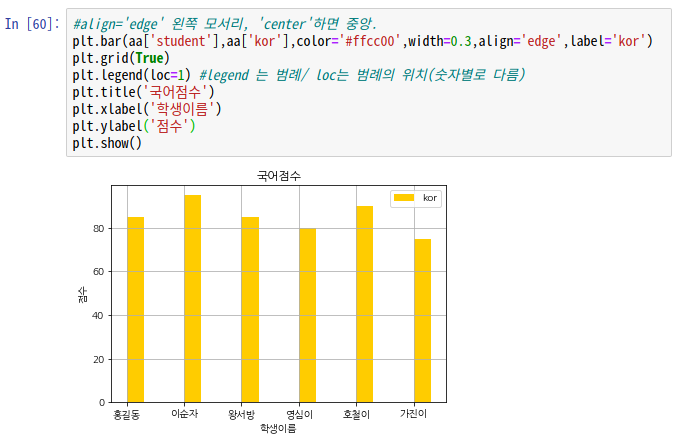
plt.bar(aptGroupby.index,aptGroupby['지역명'],color='#55c8ff',width=0.5,
label='경기지역') #bar(x,y)
plt.legend()
plt.title('시각화 결과')
plt.xlabel('지역명')
plt.ylabel('총 갯수')
plt.grid
plt.show()
3. 데이터를 JSON으로 바꿔서 저장하기 : to_json
궁극적으로 데이터프레임에서 만든 json을 디장고로 보내서 사용하거나 spring MVC를 사용하는 것이 목표다.
파이썬은 기본적으로 읽어들이거나 내보내는 형식이 자바에 비해 훨씬 간단하다. 읽어들이는 경우 import os 를 이용해서 w(write), r(read) 등 간단한 약어를 사용할 수 있다. 내보내기 역시 마찬가지다.
force_ascii=False : 유니코드 방지

[참고] 파일명을 쓰지 않으면 저장은 되지 않고 출력만 된다.
json으로 저장할 때 여러가지 옵션을 설정할 수 있다. 각 설정별로 결과값을 비교해보자.
- records : 컬럼에 따른 데이터만 출력(가로로 한줄씩 컬럼명을 key값으로 출력)
# records : 데이터만 출력(가로로 한줄씩 컬럼명을 key값으로 출력)
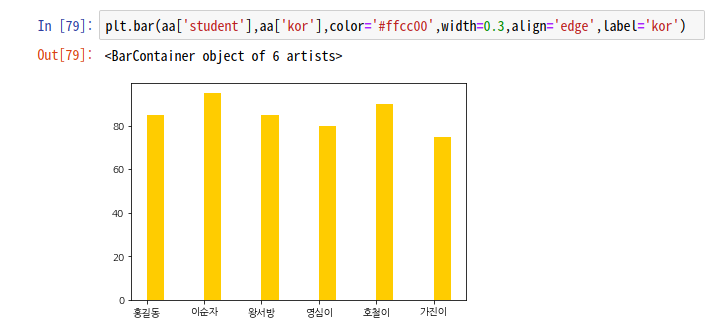
aa.to_json(orient='records', force_ascii=False)# json 데이터
[{"sno":"A001","student":"홍길동","kor":85,"eng":90,"math":85},
{"sno":"B001","student":"이순자","kor":95,"eng":95,"math":75},
{"sno":"A002","student":"왕서방","kor":85,"eng":95,"math":75},
{"sno":"B002","student":"영심이","kor":80,"eng":80,"math":100},
{"sno":"A003","student":"호철이","kor":90,"eng":65,"math":70},
{"sno":"B003","student":"가진이","kor":75,"eng":100,"math":80}]
- split : column 데이터, index 데이터, value 데이터를 나눠서 출력. key값에서 특정 칼럼이 필요할 때 사용한다.
# split : 특정 칼럼 설정
aa.to_json(orient='split',force_ascii=False)# json 데이터
{"columns":["sno","student","kor","eng","math"],
"index":[0,1,2,3,4,5],
"data":[["A001","홍길동",85,90,85],
["B001","이순자",95,95,75],
["A002","왕서방",85,95,75],
["B002","영심이",80,80,100],
["A003","호철이",90,65,70],
["B003","가진이",75,100,80]]}
- table: 스키마(데이터베이스의 전체적인 논리적 구조 / PK값, pandas 버전 등)를 추가한 데이터. 이 DateFrame과 관련된 모든 정보를 포함한다.
# table : DF 정보 포함
aa.to_json(orient='table',force_ascii=False)# json 데이터
{"schema": {"fields":[{"name":"index","type":"integer"},
{"name":"sno","type":"string"},
{"name":"student","type":"string"},
{"name":"kor","type":"integer"},
{"name":"eng","type":"integer"},
{"name":"math","type":"integer"}],
"primaryKey":["index"],
"pandas_version":"0.20.0"
},
"data": [{"index":0,"sno":"A001","student":"홍길동","kor":85,"eng":90,"math":85},
{"index":1,"sno":"B001","student":"이순자","kor":95,"eng":95,"math":75},
{"index":2,"sno":"A002","student":"왕서방","kor":85,"eng":95,"math":75},
{"index":3,"sno":"B002","student":"영심이","kor":80,"eng":80,"math":100},
{"index":4,"sno":"A003","student":"호철이","kor":90,"eng":65,"math":70},
{"index":5,"sno":"B003","student":"가진이","kor":75,"eng":100,"math":80}]
}
그냥 처음부터 정보를 제한해서 저장하는 방법도 있다.
- index : 대표 key 값을 인덱스로 준다.(column은 data의 키값이다.)
#인덱스
aa.to_json(orient='index',force_ascii=False)# json 데이터
{
"0":{"sno":"A001","student":"홍길동","kor":85,"eng":90,"math":85},
"1":{"sno":"B001","student":"이순자","kor":95,"eng":95,"math":75},
"2":{"sno":"A002","student":"왕서방","kor":85,"eng":95,"math":75},
"3":{"sno":"B002","student":"영심이","kor":80,"eng":80,"math":100},
"4":{"sno":"A003","student":"호철이","kor":90,"eng":65,"math":70},
"5":{"sno":"B003","student":"가진이","kor":75,"eng":100,"math":80}
}
- columns: 대표 key 값을 컬럼으로 준다.(index는 data의 키값이다.)
#컬럼
aa.to_json(orient='columns',force_ascii=False)# json 데이터
{
"sno":{"0":"A001","1":"B001","2":"A002","3":"B002","4":"A003","5":"B003"},
"student":{"0":"홍길동","1":"이순자","2":"왕서방","3":"영심이","4":"호철이","5":"가진이"},
"kor":{"0":85,"1":95,"2":85,"3":80,"4":90,"5":75},
"eng":{"0":90,"1":95,"2":95,"3":80,"4":65,"5":100},
"math":{"0":85,"1":75,"2":75,"3":100,"4":70,"5":80}
}
- values : 값만 묶어서 보내주자.
#값만 보내주기(키값은 나중에 설정하자.)
aa.to_json(orient='values',force_ascii=False)# json 데이터
[["A001","홍길동",85,90,85],["B001","이순자",95,95,75],["A002","왕서방",85,95,75],
["B002","영심이",80,80,100],["A003","호철이",90,65,70],["B003","가진이",75,100,80]]4. Django에서 데이터프레임을 json 데이터로 변환 후 차트 그리기
1. 우선 html 파일을 간단하게 만들자.
버튼을 누르면 json 데이터를 이용한 c3js 차트가 나오도록 하자.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<div style="width:450px;margin:auto">
<div><input type="button" value="click" id="jsonLoad"></div>
<div id="target"></div>
<!-- chart를 출력하기 위한 UI -->
<div id="chart1"></div>
</div>
<!-- C3JS 라이브러리 불러오기 -->
<script src="https://ajax.googleapis.com/ajax/libs/jquery/3.5.1/jquery.min.js"></script>
<script src="https://d3js.org/d3.v3.min.js"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/c3/0.4.11/c3.min.js"></script>
</body>
</html>버튼을 클릭하면 jsonLoad로 이동한다.
2. views.py 에서 jsonLoad를 정의해주자.
# 제이슨 파일로 바꿀 데이터프레임
def make_dfall():
df_all = pd.DataFrame({'sno': ['A001', 'B001', 'A002', 'B002', 'A003', 'B003'],
'student': ['홍길동', '이순자', '왕서방', '영심이', '호철이', '가진이'],
'kor': [85, 95, 85, 80, 90, 75],
'eng': [90, 95, 95, 80, 65, 100],
'math': [85, 75, 75, 100, 70, 80]
})
return df_all
#위에서 정의한 make_dfall를 split으로 해서 데이터를 보낸다.
def loadJson(request):
df = make_dfall()[['student', 'kor', 'eng', 'math']]
print(df)
df.to_json('test.json', orient='split', force_ascii=False)
f = open('/home/kosmo_03/PycharmProjects/myapps/test.json')
aa = json.load(f)
print(aa)
return JsonResponse(aa, json_dumps_params={'ensure_ascii': False}, safe=False)
#데이터 로드 후 JsonResponse로 로드한 aa를 응답해주자.
3. urls.py 에 링크 등록한다.
# -------------------------------------------------
path('chart3', views.chart3),
path('loadJson', views.loadJson),
4. chart3.html에 script를 추가한다.
버튼을 누르면 차트가 나온다. 차트를 누르는 버튼의 id를 jsonLoad으로 했으므로, 그 기능을 심어주자.
$('#jsonLoad').click(function(){ : html에서 정의한 id가 jsonLoad인 값을 클릭하면 함수 실행.
ajax를 자세히 보면,
url:'loadJson' : url.py에 정의한 요청이 들어오면 정의한 뷰를 실행한다.
function(data) : 실행에 성공하면, data(=view에서 응답한 aa) 를 이용해서 차트를 만드는 makeBarChart 함수를 실행한다. 단, data(=aa)의 data 컬럼과, columns컬럼을 키값으로 가진 value 값을 가져온다.

<script>
$(function(){
$('#jsonLoad').click(function(){
//아이디가 jsonLoad인 값을 클릭하면 함수 실행.
$.ajax({
url:'loadJson',
//url.py에 정의한 요청이 들어오면 정의한 뷰가 실행 .있는것 중 loadJson 가져와
success:function(data){ //여기 데이터는 view에서 response한 aa
makeBarChart(data.data,data.columns); //makeBarChart function 실행해(아래에 있는거)
//제이슨 데이터 안에 있는 data와 columns를 가져온다.
} //end success
});//end ajax
}); //click end
}); //end $(function(){
</script>
</body>
</html>
5. 데이터 차트에 맞게 수정
일단 데이터는 가지고 왔다. 하지만 우리가 필요한 데이터를 정제할 필요가 있다.
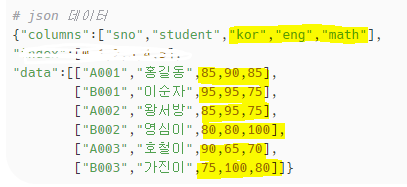
function makeBarChart(jsonData, dcol){
var datas = [];
// [n개의 컬럼들]
var dcolumns = dcol.slice(1, dcol.length);
//첫번째 컬럼 슬라이스
for(var key in jsonData){ //jsonData : 실제 이름, 점수 데이터
datas.push(jsonData[key]); //2. 배열에 저장한다.
}차트를 만드는 makeBarChart 함수를 정의하자. dcol과 jsonData가 컬럼과 data인가?
우선 jsonData와 dcol 이라는 변수를 쓸건데, 각각 차트에 필요한 이름, 점수값을 가진 배열과 컬럼명이다.
컬럼명은 원래 제일 왼쪽에 있는 애가 컬럼명이 되었다. 이걸 잘라주자.
var dcolumns = dcol.slice(1,dcol.length);

for문을 이용해서 남은 파란색 jsonData를 datas에 넣어준다.

c3를 생성한다.
1) data를 설정할 때, 컬럼이 위에서 파란색으로 넣은 데이터다. 맨 왼쪽에 있는 것(이름)이 인덱스가 된다.
2) axis 축을 설정하는데 x축을 남은 노란색 컬럼으로 지정한다.

function makeBarChart(jsonData, dcol){
var datas = [];
// [n개의 컬럼들]
var dcolumns = dcol.slice(1, dcol.length);
//첫번째 컬럼 슬라이스
for(var key in jsonData){ //jsonData : 실제 이름, 점수 데이터
datas.push(jsonData[key]); //2. 배열에 저장한다.
}
//c3js.com bar 샘플 코드를 복사
var chart = c3.generate({
bindto : '#chart1',
data: {columns: datas, type: 'bar'},// jsonData를 바인딩한다.
bar: {width: {ratio: 0.5} },
axis: { x: {type: 'category',categories: dcolumns} }
// X축에 읽어온 컬럼의 category 를 지정한다.
});//end var chart
}// end function makeBarChart
}); //end $(function(){
</script>
실행 후 버튼을 누르면,

▼ 전체 코드
views.py
urls.py
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<div style="width:450px;margin:auto">
<div><input type="button" value="click" id="jsonLoad"></div>
<div id="target"></div>
<!-- chart를 출력하기 위한 UI -->
<div id="chart1"></div>
</div>
<!-- C3JS 라이브러리 불러오기 -->
<script src="https://ajax.googleapis.com/ajax/libs/jquery/3.5.1/jquery.min.js"></script>
<script src="https://d3js.org/d3.v3.min.js"></script>
<script src="https://cdnjs.cloudflare.com/ajax/libs/c3/0.4.11/c3.min.js"></script>
<script>
$(function(){
$('#jsonLoad').click(function(){
//아이디가 jsonLoad인 값을 클릭하면 함수 실행.
$.ajax({
url:'loadJson', //url.py에 정의한 요청이 들어오면 정의한 뷰가 실행 .있는것 중 loadJson 가져와
success:function(data){ //여기 데이터는 view에서 response한 aa
makeBarChart(data.data,data.columns); //makeBarChart function 실행해(아래에 있는거)
//제이슨 데이터 안에 있는 data와 columns를 가져온다.
} //end success
});//end ajax
}); //click end
function makeBarChart(jsonData, dcol){
var datas = [];
// [n개의 컬럼들]
var dcolumns = dcol.slice(1, dcol.length);
//첫번째 컬럼 슬라이스
for(var key in jsonData){ //jsonData : 실제 이름, 점수 데이터
datas.push(jsonData[key]); //2. 배열에 저장한다.
}
//c3js.com bar 샘플 코드를 복사
var chart = c3.generate({
bindto : '#chart1',
data: {columns: datas, type: 'bar'},// jsonData를 바인딩한다.
bar: {width: {ratio: 0.5} },
axis: { x: {type: 'category',categories: dcolumns} }
// X축에 읽어온 컬럼의 category 를 지정한다.
});//end var chart
}// end function makeBarChart
}); //end $(function(){
</script>
</body>
</html>views.py
def chart3(request):
return render(request, "survey/chart3.html")
def loadJson(request):
df = make_dfall()[['student', 'kor', 'eng', 'math']]
print(df)
df.to_json('test.json', orient='split', force_ascii=False)
f = open('/home/kosmo_03/PycharmProjects/myapps/test.json')
aa = json.load(f)
print(aa)
return JsonResponse(aa, json_dumps_params={'ensure_ascii': False}, safe=False)
def make_dfall():
df_all = pd.DataFrame({'sno': ['A001', 'B001', 'A002', 'B002', 'A003', 'B003'],
'student': ['홍길동', '이순자', '왕서방', '영심이', '호철이', '가진이'],
'kor': [85, 95, 85, 80, 90, 75],
'eng': [90, 95, 95, 80, 65, 100],
'math': [85, 75, 75, 100, 70, 80]
})
return df_allurls.py
# -------------------------------------------------
path('chart3', views.chart3),
path('loadJson', views.loadJson),
]
'[ Python ]' 카테고리의 다른 글
| [Python] SciPy / 기초기술통계 / ANOVA(분산분석) / 회귀분석 (0) | 2020.11.02 |
|---|---|
| [Python] SciPy / 기초기술통계 / 카이제곱검정 / T검정 (0) | 2020.10.30 |
| [Python] Pandas 기초 / DataFrame / matplotlib / 실습(2) (0) | 2020.10.29 |
| [python] 주피터 노트북(jupyter notebook) 단축키 (0) | 2020.10.28 |
| [Python] Pandas 기초/ Series /DataFrame / 실습(1) (0) | 2020.10.28 |