
# wikidocs.net을 보고 요약 및 정리
머신러닝
사람에게 사진을 보고 고양이와 강아지를 구분하라고 하면 쉽지만 기계는 그렇지 않다. 기계는 이미지를 분류하기 위해 이미지의 shape이나 edge를 판별하고 찾아 알고리즘화를 하려고 하지만 한계는 존재한다. 이럴때 머신러닝이 해결책이 될 수 있다. 머신러닝은 데이터와 해답을 주고 기계에게 비슷한 예제를 학습시켜 규칙성을 만든다.
즉, 머신러닝은 "주어진 데이터로부터 규칙성을 찾는 것"이다.
머신러닝 모델은 일반적으로 훈련용, 검증용, 테스트용으로 분리해서 사용한다. 훈련용으로 모델을 훈련하고, 검증용에서 모델의 성능을 조정한 뒤(과적합 판단, 하이퍼파라미터) 조정 등), 튜닝한 검증용 데이터를 아직 보지못한 데이터, 테스트 데이터로 모델의 진짜 성능을 평가한다. 문제지, 모의고사, 수능시험으로 비유를 들 수 있다.
+ 추가로 데이터가 충분하지 않아 나눌 수 없다면 k-fold 교차검증이라는 방법을 쓰기도 한다.
변수의 속성 : 하이퍼파라미터와 매개변수
하이퍼파라미터는 모델의 성능에 영향을 주는 매개변수이고, 사용자가 직접 정해줄 수 있다. (ex.학습률) 훈련 이후 검증하면서 하이퍼파라미터를 튜닝한다.
매개변수는 모델이 학습하는 과정에서 얻어지는 값이다. ex)가중치, 편향
러닝? 어떤걸 학습할까? : 지도학습, 비지도학습, 강화학습
지도학습은 훈련데이터를 훈련시킬 때 문제지를 주고 답을 암기시키는 방법이다. 문제에 해당하는 답을 학습하고, 새로운 문제를 봤을 때 정답을 예측한다. 여기에 분류와 회귀가 있다. ex)스팸분류기
비지도학습은 답이 없다. 단, 각각의 데이터의 특징을 분석해서 비슷한 형태를 찾아내는 학습을 한다. 즉, 군집화한다.ex)다리 4개인 동물, 다리가 2개인 동물 군집화
강화학습은 배우지 않겠지만 상과 벌점 제도가 있어서 벌을 최소화시키는 방식이다. 알파고와 게임의 최적 동작을 찾는 방법.
어떤 문제에 대해 다룰까? : 분류와 회귀
머신러닝은 많은 문제에서 분류 또는 회귀에 해당한다. 선형회귀는 회귀문제에 대해 학습하고, 로지스틱 회귀는 이름은 회귀이지만 분류문제를 학습한다. 분류는 이진분류와 다중클래스분류로 나뉜다.
(추가로 다중레이블 분류도 있으나 이건 어려우니 패스.)
회귀는 분류처럼 0 또는 1, 분리된 카테고리 이런 답이 결과가 아니라 연속된 값이 결과다. 시간에 따른 주가 예측, 생산량예측, 결과 예측 등등이 있다.
분류는 답을 정한다. 이진분류는 주어진 입력에 대해서 둘 중 하나의 답을 정한다.(ex. 합격/불합격, 스팸/정상메일)
다중클래스분류는 주어진 입력에 대해서 두개 이상의 정해진 선택지 중에서 답을 정하는 것. 입력값이 들어오면 카테고리를 판단해서 적절한 곳에 판단된다.
어떤 데이터를 다룰까? : 샘플과 특성
많은 머신 러닝 문제가 1개 이상의 독립 변수 xx를 가지고 종속 변수 yy를 예측하는 문제이다. 신경망에서 우리는 훈련데이터를 행렬로 표현을 많이하게 되는데, 독립변수 x의 행렬을 그 갯수만큼 나열한다. 여기서 가로줄은 샘플(DB에서는 레코드), 세로줄은 종속변수 y를 예측하기 위한 특성이라한다.
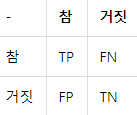
데이터 분석 이후 결과 : 정확도, 혼동행렬, 정밀도, 재현률
우리는 학습을 시키기 때문에 테스트 데이터에서 정확도(맞춘거/전체)가 높을수록 좋다. 근데 우리가 학습시키는 대답이 긍정이었는지, 부정이었는지를 알 수 없다. 그냥 정확도만 확인한다고 좋은게 아니기 때문에... 그래서 혼동행렬이라는 행렬을 만들어서, 각 대답에 대한 긍부정, 결과, 그리고 정밀도와 재현률을 알 수 있다.


머신러닝에서 고려해야할 점 : 과적합, 과소적합
여기까지 테스트 데이터에 대한 결과를 보는 방법과, 답변의 방향성까지 보게 되었다. 근데 여기서 예상치 못한 에러가 날 수 있지 않을까? 그걸 방지하는 두가지 방법.
과적합은 지금 이 모델이 이 훈련데이터에 딱 맞게 만들어진 모델이라 생기는 오류이다. 그럼 훈련은 겁나 좋게 나왔는데 테스트에서는 원하는만큼의 결과치가 나오지 않는다. 이건 훈련데이터를 지나치게 일반화한 것. 에포크(훈련횟수)가 많아질수록 비슷한 데이터로 학습시킨 것이기 때문에 과적합이 생긴다. 반대로 너무 훈련을 덜하면 배울 수 있는 여지가 있는데도 기회를 안준 것이므로 과소적합이라고 부른다. 적합(fit)이라는 단어는 모델이 주어진 데이터에 대해서 적합해져가는 과정이기 때문에 붙여졌다. 케라스에서는 학습시키는 도구 이름을 fit이라고 부르기도 한다.
회귀분석
회귀부터 하자. 선형회귀는 ~할수록 ~하다 라는 말이 딱이다. 한 변수값(x)의 변화에 따라 특정 변수의 값(y)이 영향을 받는다. x가 하나면 단순선형회귀다. 다중선형회귀는 여기서 wx가 여러개 있는것이다. 집가격은 집 평수 뿐만 아니라, 방의 갯수, 역세권 등 여러 영향이 있다. 독립변수가 여러개면 다중선형회귀이다.
단순선형회귀는 1차함수 수식을 쓴다.( y=Wx+b )여기서 기울기에 해당하는 w와 절편을 의미하는 b는 각각 가중치와 편향을 뜻한다. 어차피 변수값은 뭘 넣느냐에 따라 y값이 그거에 맞게 나오기 때문에, 그 변화의 폭, 또는 변화의 질을 바꾸는 것은 가중치와 편향이다. 따라서 적절한 w와 b의 값을 찾아내야 x와 y의 관계를 적절히 모델링한 것이라 볼 수 있다.
일단 비용함수(=손실함수, 목적함수)를 구해야 한다. 이건 함수의 값을 최소화하거나 최대화하는 목적을 가진 함수이다. 여기서 우리가 최소화 하는 것은 예측값의 오차이다. 즉, 회귀식인 예측값과 실제값(점)의 거리를 최소화해야 한다. 여기서는 MSE(평균 제곱 오차)라는 것을 쓰고, 이것은 임의로 그린 회귀선을 서서히 w와 b값을 바꿔가면서 최소화하는 값들을 찾는다. 각각 점과 선 사이의 거리를 절댓값 처리를 위해 제곱해주고 그걸 갯수로 나눠서 평균을 냈다.

이게 최소가 되어야하는데 그때 최적의 알고리즘을 옵티마이저(Optimizer)라고 한다. 가장 기본적인 옵티마이저 알고리즘인 경사하강법을 써보자.
경사하강법(Gradient Descent)
따로 절편 상관 없이 가장 극단적인 양 극단을 그려보면 가운데로 올 수록 오차가 줄어드는 2차함수 형태로 그려진다. (x: w(기울기) y:오차율 => MSE) 이 오차가 최소인 지점을 우리는 극점으로 배웠다. 편미분 써서 값 찾고 등등... 접선의 기울기가 =0 인 지점을 찾는다. 컴퓨터에서는 임의의 w,b값에서 학습률(learning rate)이라는 하이퍼파라미터(개발자가 설정하는 값)를 정해서 조금씩 극단으로 다가간다. 여기서 학습률이 너무 크면 최소값을 넘어 반대편으로 넘어가니(=발산) 조심해야한다.


선형회귀에서 가장 적합한 비용함수와 옵티마이저는 MSE와 경사하강법이다.
코딩 방법)
케라스에서 구현한다. activation을 선형으로 설정하고, 컴파일 loss를 mse로 한다. 모델을 학습률 0.01로 해서 fit한다. 그러면 주어진 x와 y에 대해서 오차를 최소화하는 작업을 epochs만큼 시도한다.
어느순간 하다가 MSE가 정해져서 오차가 줄어들지 않는다. predict 하면 그 모델의 예측값이 나온다.
이진분류
둘 중 하나 선택하고 분류하는 것. 대표적으로 0과 1만 출력하는 계단함수, 또는 시그모이드 함수 같은 것이 있다. 이 그래프들은 극단적으로 둘중에 하나만 선택하기 때문에 s자 형태를 띈다. 실험을 하려고 해도 직선으로는 안되고 s자 그래프가 필요하다는 소리. 선형회귀는 둘 중 하나이기 때문에 선형회귀분석처럼 직선의 방정식으로 표현하기 힘들다.

이런 문제들을 풀기 위해 s자 형태인 시그모이드 함수를 사용한다. σ(Wx+b) 대충 이런 형태를 갖는데, 시그모이드는 출력값을 0과 1 사이의 값으로 조정해서 반환하고, x가 0일 때 0.5인 중간값을 가진다. 굴곡지지 않게 부드럽게 이어준 그래프라는 소리. 그래서 그 기준을 0.5로 두고 0.5 이상이면 1로 판단하고 그 이하면 0으로 판단한다. 확률로 따지면 50%라는 소리.
왜 얘는 경사하강법 못해?
그래프의 저점이 여러 개다. 이떄 크로스 엔트로피(Cross Entropy)함수를 사용하는데, 이 함수는 데이터의 개수와 범주 개수, 실제값(0과1)과 실제 값에 대한 확률로 계산하는 비용함수이다. 이거는 말 그대로 엔트로피, 불확실성에 대한 척도를 나타내는 수식이다. 1이나 0인경우 말고, 그 중간의 지점을 어느쪽에 치우쳐져있나 판단하는 것.
즉 로지스틱 회귀는 비용함수로 크로스 엔트로피 함수를 사용하며, 가중치를 찾기 위해서 크로스 엔트로피 함수의 평균을 취한 함수를 사용한다. 크로스 엔트로피 함수는 소프트맥스 회귀 비용 함수이기도 하다.
'[ Python ]' 카테고리의 다른 글
| [Python] SciPy / 기초기술통계 / ANOVA(분산분석) / 회귀분석 (0) | 2020.11.02 |
|---|---|
| [Python] SciPy / 기초기술통계 / 카이제곱검정 / T검정 (0) | 2020.10.30 |
| [Python] Pandas 기초 / groupby / 데이터프레임 Json으로 저장 / 실습(3) (0) | 2020.10.30 |
| [Python] Pandas 기초 / DataFrame / matplotlib / 실습(2) (0) | 2020.10.29 |
| [python] 주피터 노트북(jupyter notebook) 단축키 (0) | 2020.10.28 |